Entrenamiento
Contents
3. Entrenamiento#
3.1. Introducción#
Como lo hemos visto en la primera parte, el reconocimiento entidades nombradas (NER) es una tarea de NLP muy estudiada que consiste en predecir etiquetas semánticas superficiales para una secuencia de palabras.
Los enfoques actuales para el NER consisten en aprovechar arquitecturas de transformadores pre-entrenados, como [Devlin et al., 2019] o [Lample and Conneau, 2019]. Esos transformadores han sido pre-entrenados en otras tareas sobre un corpus grande y sirven de base para entrenar modelos de NER transfiriendo su aprendizaje previo a esa tarea (véase la Section 5.1 del anexo).
Esos enfoques suelen considerar el texto a nivel de frase, exactamente como lo hemos hecho en el dominio jurídico, y por lo tanto no modelan la información que cruza los límites de la frase (Por una introducción a este enfoque así como un ejemplo de uso completo véase Section 5.4). Podemos hacerlo pasando una frase con su contexto circundante. Sin embargo, el uso de un modelo basado en transformadores para NER ofrece una opción natural para capturar características a nivel de documento. Como muestra Fig. 3.1, este contexto puede influir en la representación de las palabras de una frase: La frase de ejemplo: “I love Paris”, pasa por el transformador junto con la siguiente frase que comienza con “The city is”, ayudando potencialmente a resolver la ambigüedad de la palabra “Paris”.
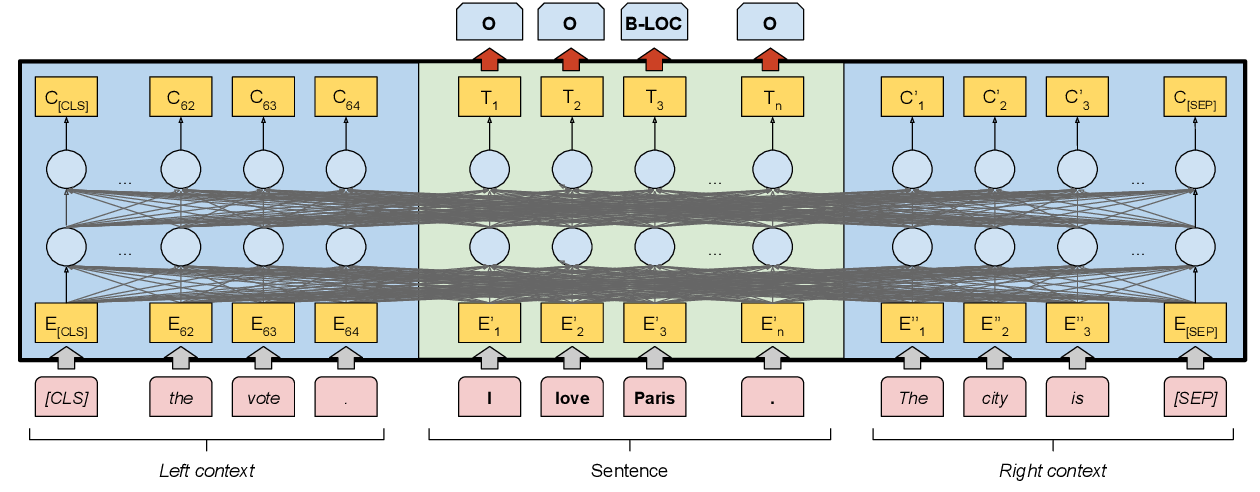
Fig. 3.1 Para obtener características a nivel de documento para una frase que deseamos etiquetar (“I love Paris”, sombreada en verde), añadimos 64 tokens a la izquierda y a la derecha (sombreados en azul). Como el transformador calcula la auto-atención sobre todos los tokens de entrada, la representación de los tokens de la frase está influida por el contexto izquierdo y derecho.#
Esto es exactamente lo que propone el nuevo enfoque Flert [Schweter and Akbik, 2020] disponible en la biblioteca Flair [Akbik et al., 2019] que roza el estado del arte.
Note
Hacer respetar los límites de los documentos. Los autores de Flert [Schweter and Akbik, 2020] demuestran que el respeto de los límites de los documentos aumenta el escore \(F_{1} micro\) en casi todos sus experimentos y recomiendan su cumplimiento si es posible. Su expectativa inicial de que los transformadores aprenderían automáticamente a respetar los límites de los documentos no se materializó. La aplicación de los límites del documento consiste en una ablación en la que se truncan las características del documento en los bordes del mismo, lo que significa que el contexto sólo puede proceder del mismo documento.
En la literatura, hay dos enfoques conceptualmente muy diferentes para el NER basado en transformadores que se utilizan actualmente, los dos son basados en el Transfer Learning. Evaluaremos las características de los documentos en ambos:
En el primero, afinamos el propio transformador en la tarea NER y solo añadimos una capa lineal para las predicciones a nivel de palabra [Devlin et al., 2019] .
En el segundo, utilizamos el transformador solo para proporcionar características a una arquitectura de etiquetado de secuencias LSTM-CRF [Huang et al., 2015] estándar y, por tanto, no realizamos ningún ajuste fino. Hemos utilizado la arquitectura LSTM-CRF previamente para el dominio judicial pero con los words embeddings contextuales de Flair [Akbik et al., 2018] y embeddings estáticos como word2vec [Mikolov et al., 2013].
Discutimos las diferencias entre ambos enfoques y exploramos los mejores hiperparámetros para cada uno, manualmente y con ayuda de la biblioteca Hyperopt. En su mejor configuración determinada, realizamos una evaluación comparativa a la cual integramos los mejores modelos entrenados con embeddings contextuales de Flair [Akbik et al., 2018] con o sin embeddings estáticos [Mikolov et al., 2013] junto con la arquitectura LSTM-CRF (i.e. la mejor arquitectura sobre la tarea de anonimización de documentos judiciales).
Características a nivel de documento
El enfoque de Flert, que consiste en crear un contexto por cada frase, tiene ventajas computacionales, ya que cada frase y su contexto sólo tienen que pasar por el transformador una vez y el contexto añadido se limita a una ventana relativamente pequeña. Además, sigue siendo posible seguir el procedimiento estándar de mezclar las frases en cada momento del entrenamiento, ya que el contexto se codifica por frases.
3.2. Experimentos con parámetros de referencia#
Como se ha mencionado en la introducción, existen dos arquitecturas comunes para el NER basado en transformadores, a saber, los enfoques de ajuste fino y los basados en características. En esta sección, presentamos brevemente las diferencias entre ambos enfoques y realizamos un estudio para identificar los mejores hiperparámetros para cada uno. Las mejores configuraciones de cada se utilizan luego en la evaluación comparativa final en la sección Evaluación comparativa.
3.2.1. Configuración#
- Dataset
Utilizamos el conjunto de datos de desarrollo de MEDDOCAN 1.
- Modelo de transformador
En todos los experimentos de esta sección, empleamos 2 modelos de transformadores:
El modelo de transformador XLM-Roberta (XLMR) propuesto por [Lample and Conneau, 2019]. En nuestros experimentos utilizamos xlm-roberta large, entrenado en 2,5TB de datos del corpus limpio Commom Crawl [Wenzek et al., 2020] para 100 idiomas diferentes.
El modelo de transformador BERT propuesto por [Devlin et al., 2019]. En nuestros experimentos utilizamos BETO, un modelo bert entrenado en el gran corpus español [Cañete et al., 2020].
- Embeddings (+ WE)
Para cada configuración experimentamos concatenando embeddings de palabras clásicas a las representaciones a nivel de palabra obtenidas del modelo transformador. Utilizamos los embeddings de FastText en español [Bojanowski et al., 2017] estabilizados [Antoniak and Mimno, 2018].
3.2.2. Primera estrategia: Ajuste fino#
Las estrategias de ajuste fino suelen añadir una sola capa lineal a un transformador y ajustan toda la arquitectura en la tarea NER. Para hacer el puente entre el modelado de subtokens y las predicciones a nivel de tokens, aplican la agrupación de subpalabras para crear representaciones a nivel de tokens que luego se pasan a la capa lineal final. Conceptualmente, este enfoque tiene la ventaja de que todo se modela en una única arquitectura que se ajusta en su conjunto. En la Section 5.2.1 del anexo se dan más detalles sobre los parámetros y la arquitectura.
Evaluamos esta estrategia con los transformadores BETO [Cañete et al., 2020] y XLMR [Lample and Conneau, 2019]. Los resultados figuran en la tabla 3.2.
| Track | Subtrack 1 | Subtrack 2 [Strict] | Subtrack 2 [Merged] | |
|---|---|---|---|---|
| Transformador | Estrategia | |||
| XLMR LARGE | Transformador lineal | 97.56 ± 0.16 | 98.0 ± 0.17 | 98.62 ± 0.1 |
| + Context | 97.51 ± 0.09 | 97.94 ± 0.09 | 98.53 ± 0.03 | |
| + WE | 97.51 ± 0.12 | 97.93 ± 0.13 | 98.63 ± 0.09 | |
| BETO | Transformador lineal | 97.38 ± 0.21 | 97.93 ± 0.16 | 98.56 ± 0.1 |
| + Context | 97.32 ± 0.1 | 97.84 ± 0.1 | 98.52 ± 0.03 | |
| + WE | 97.3 ± 0.08 | 97.8 ± 0.1 | 98.55 ± 0.1 | |
| + WE + Context | 97.4 ± 0.16 | 97.96 ± 0.18 | 98.66 ± 0.06 |
Fig. 3.2 Evaluación de diferentes transformadores mediante el proceso de ajuste fino. La evaluación se realiza contra el conjunto de desarrollo.#
3.2.3. Segunda estrategia: Basado en características#
En cambio, los enfoques basados en características utilizan el transformador solo para generar embeddings para cada palabra de una frase y las utilizan como entrada en una arquitectura de etiquetado de secuencias estándar, normalmente una LSTM-CRF [Huang et al., 2015]. Los pesos del transformador se congelan para que el entrenamiento se limite al LSTM-CRF. Conceptualmente, este enfoque se beneficia de un procedimiento de entrenamiento del modelo bien entendido que incluye un criterio de parada real. En la Section 5.2.2 del anexo se dan más detalles sobre los parámetros y la arquitectura. En nuestros experimentos solo evaluamos una variante de las dos propuestas en [Schweter and Akbik, 2020] porque suele dar los mejores resultados.
- Media de todas las capas
Obtenemos embeddings para cada token utilizando la media de todas las capas producidas por el transformador, incluida la capa de embeddings de palabras. Esta representación tiene la misma longitud que el tamaño oculto de cada capa transformadora. Este enfoque se inspira del “scalar mix” del estilo ELMO [Peters et al., 2018].
Los resultados se encuentran en la tabla 3.3.
| Track | Subtrack 1 | Subtrack 2 [Strict] | Subtrack 2 [Merged] | |
|---|---|---|---|---|
| Estrategia | computation | |||
| LSTM CRF | BETO (Ultimas 4 capas) | 97.25 ± 0.07 | 97.9 ± 0.02 | 98.47 ± 0.06 |
| + Context | 97.04 ± 0.08 | 97.6 ± 0.1 | 98.36 ± 0.13 | |
| + WE | 97.35 ± 0.18 | 97.94 ± 0.17 | 98.56 ± 0.14 | |
| + WE + Context | 97.46 ± 0.1 | 98.02 ± 0.11 | 98.59 ± 0.04 |
Fig. 3.3 Evaluación de la estrategia basada en características. La evaluación se realiza contra el conjunto de desarrollo.#
3.2.4. Flair baseline#
De la misma mañera usamos los embeddings contextuales de Flair [Akbik et al., 2018] como entrada de la arquitectura LSTM-CRF [Huang et al., 2015]. En la Section 5.2.2.2 del anexo se dan más detalles sobre los parámetros y la arquitectura. Esa arquitectura nos sirve de referencia con los resultados anteriores obtenidos con los datos jurídicos.
Los resultados se encuentran en la tabla 3.4.
| Track | Subtrack 1 | Subtrack 2 [Strict] | Subtrack 2 [Merged] | |
|---|---|---|---|---|
| Estrategia | Embeddings | |||
| LSTM CRF | FLAIR | 97.32 ± 0.08 | 97.93 ± 0.06 | 98.53 ± 0.05 |
| + WE | 96.75 ± 0.07 | 97.24 ± 0.1 | 98.27 ± 0.06 |
Fig. 3.4 Evaluación de la estrategia basada en características con los embeddings de Flair. La evaluación se realiza contra el conjunto de desarrollo.#
3.2.5. Resultados: Mejor configuración#
Evaluamos ambos enfoques en cada variante en todas las combinaciones posibles añadiendo embeddings de palabras estándar “(+ WE)” y características a nivel de documento “(+ Contexto)”. Cada configuración se ejecuta tres veces para reportar el promedio de \(F_{1} micro\) y la desviación estándar para cada una de las 3 opciones: NER, Span y Span Merged.
- Results
Para el ajuste fino, vemos que la adición de embeddings estáticos, así como el uso del contexto, no parecen mejorar los resultados tanto para BETO como para XLMR (véase tabla 3.2). La configuración “WE + CONTEXT” parece dar los mejores resultados. Sin embargo, hay que señalar que, por falta de recursos, no hemos podido realizar el entrenamiento con la configuración “XLMR + WE + CONTEXT” que podía haber dado buenos resultados. Vemos que el uso de XLMR permite mejorar los resultados en comparación con BETO. Para el enfoque basado en características, encontramos también que la configuración “WE + CONTEXT” produce muy claramente los mejores resultados (véase tabla 3.3). Para el modelo de referencia con “Flair + LSTM CRF” la adición de embeddings estáticos “(+ WE)” tiene un impacto negativo (véase tabla 3.4).
3.3. Evaluación comparativa#
Con las configuraciones identificadas en Experimentos con parámetros de referencia en los datos de desarrollo, realizamos una evaluación comparativa final en los datos de test, con y sin características de los documentos.
3.3.1. Principales resultados#
Los resultados de la evaluación se recogen en la Tabla 3.5. Hacemos las siguientes observaciones:
| Track | Subtrack 1 | Subtrack 2 [Strict] | Subtrack 2 [Merged] | |
|---|---|---|---|---|
| Estrategia | Embeddings | |||
| FINETUNE | BETO | 97.19 ± 0.05 | 97.78 ± 0.07 | 98.5 ± 0.15 |
| BETO + CONTEXT | 97.37 ± 0.16 | 97.97 ± 0.15 | 98.58 ± 0.1 | |
| BETO + WE | 97.31 ± 0.09 | 97.89 ± 0.02 | 98.63 ± 0.07 | |
| BETO + WE + CONTEXT | 97.28 ± 0.12 | 97.9 ± 0.03 | 98.54 ± 0.1 | |
| XLMRL | 97.59 ± 0.13 | 98.14 ± 0.09 | 98.72 ± 0.08 | |
| XLMRL + WE | 97.51 ± 0.14 | 98.11 ± 0.14 | 98.73 ± 0.09 | |
| XLMRL + CONTEXT | 97.49 ± 0.07 | 98.01 ± 0.07 | 98.65 ± 0.05 | |
| LSTM CRF | BETO | 97.2 ± 0.05 | 97.82 ± 0.07 | 98.5 ± 0.05 |
| BETO + CONTEXT | 97.09 ± 0.09 | 97.78 ± 0.06 | 98.44 ± 0.1 | |
| BETO + WE | 97.37 ± 0.07 | 97.94 ± 0.04 | 98.63 ± 0.06 | |
| BETO + WE + CONTEXT | 97.5 ± 0.06 | 98.09 ± 0.08 | 98.67 ± 0.09 | |
| FLAIR | 96.88 ± 0.13 | 97.64 ± 0.16 | 98.37 ± 0.12 | |
| FLAIR + WE | 96.84 ± 0.13 | 97.31 ± 0.11 | 98.44 ± 0.08 |
Fig. 3.5 Evaluación comparativa de las mejores configuraciones de los enfoques de ajuste fino y basados en características en los datos de test.#
El uso de Transformers sobre el dataset Meddocan nos permite una ganancia en todas las configuraciones en comparación con el uso de Flair (véase la Tabla 3.6). El mejor modelo se obtiene con la configuración “FINETUNE + XMLR”.
Note
Con los resultados obtenidos, Flert habría ganado la competición [Marimon et al., 2019] por delante del actual ganador Lukas Lange [Lange et al., 2019] (véase Tabla 3.1) que uso la libraría FLair también.
Subtrack1 |
Subtrack2 [Strict] |
Subtrack2 [Merged] |
|---|---|---|
96.96 |
97.49 |
98.53 |
En cuanto a los enfoques de “FINETUNE + LINEAR” y basado en “FEATURE BASED + LSTM CRF”, los resultados son bastante similares, aunque el segundo enfoque se ve afectado negativamente por el contexto y el primero positivamente. Por otro lado, la estrategia “FEATURE BASED + LSTM CRF + CONTEXTO + WE” es la más beneficiada con la mejor puntuación \(F_{1} micro\) en las 3 tareas si usamos BETO. Como no hemos usado la estrategia “FEATURE BASED + LSTM CRF” para XLMR nos podemos concluir. Al contrario de los resultados obtenidos por los autores de Flert [Schweter and Akbik, 2020] los resultados no son tan claros entre cada opción como en el caso del dataset CONLL03 [Sang and Meulder, 2003].
| Track | Subtrack 1 | Subtrack 2 [Strict] | Subtrack 2 [Merged] | |
|---|---|---|---|---|
| Estrategia | Embeddings | |||
| FINETUNE | BETO | 0.31 | 0.14 | 0.13 |
| BETO + CONTEXT | 0.49 | 0.32 | 0.21 | |
| BETO + WE | 0.43 | 0.24 | 0.26 | |
| BETO + WE + CONTEXT | 0.40 | 0.25 | 0.16 | |
| XLMRL | 0.71 | 0.50 | 0.35 | |
| XLMRL + WE | 0.64 | 0.46 | 0.36 | |
| XLMRL + CONTEXT | 0.61 | 0.37 | 0.28 | |
| LSTM CRF | BETO | 0.32 | 0.18 | 0.13 |
| BETO + CONTEXT | 0.21 | 0.14 | 0.07 | |
| BETO + WE | 0.49 | 0.29 | 0.26 | |
| BETO + WE + CONTEXT | 0.62 | 0.45 | 0.30 |
Fig. 3.6 Evaluación de las mejoras en score \(F_{1} micro\) en los datos de test en comparación con la opción FLAIR + WE + LSTM CRF.#
3.4. Conclusión#
El sistema basado en Transfer Learning y el uso de Transformadores (BERT / XLMR-Large) nos ha permitido obtener muy buenos resultados sobre el conjunto de datos MEDDOCAN, nos ha mostrado un score \(F_{1} micro\) superior en comparación con el uso de las tecnologías precedentes como los embeddings contextuales de Flair. No obstante esa mejora conlleva un tiempo de entrenamiento más largo (véase la Tabla 5.6) así que modelos con más parámetros y entonces más voluminosos (véase la Tabla 5.7) .
La anonimización de un documento en bruto utilizando uno de nuestros modelos se trata en la Section 5.3.1 del apéndice.