Training
Contents
5.2. Training#
Este anexo presenta algunos aspectos prácticos del entrenamiento.
5.2.1. Entrenamiento: Método de ajuste fino#
Los enfoques de ajuste fino suelen añadir una sola capa lineal a un transformador y ajustan toda la arquitectura en la tarea NER. Para hacer el puente entre el modelado de subtokens y las predicciones a nivel de tokens, los autores de Flert aplican la agrupación de subpalabras para crear representaciones a nivel de tokens que luego se pasan a la capa lineal final. Conceptualmente, este enfoque tiene la ventaja de que todo se modela en una única arquitectura que se ajusta en su conjunto.
Una estrategia común de agrupación de subpalabras es “first” [Devlin et al., 2019], que utiliza la representación del primer subtoken para todo el token. Véase la Fig. 5.3 para una ilustración.
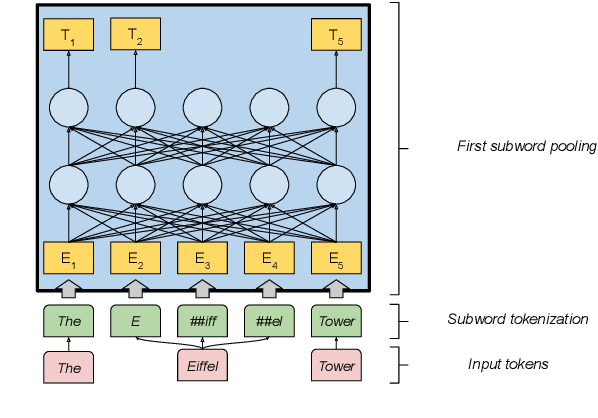
Fig. 5.3 Ilustración de la primera agrupación de subpalabras. La entrada “The Eiffel Tower” se subdivide, dividiendo la palabra “Eiffel” en tres subpalabras (sombreadas en verde). Sólo la primera (“E”) se utiliza como representación de “Eiffel”.#
5.2.1.1. Procedimiento de entrenamiento#
Para entrenar esta arquitectura, los trabajos anteriores suelen utilizar el optimizador AdamW [Loshchilov and Hutter, 2019], un ritmo de aprendizaje muy pequeña y un número pequeño y fijo de iteraciones como criterio de parada codificado [Lample and Conneau, 2019]. En Flert adoptan una estrategia de entrenamiento de un ciclo [Smith, 2018], inspirada en la implementación de los transformadores HuggingFace [Wolf et al., 2019], en la que el ritmo de aprendizaje disminuye linealmente hasta llegar a 0 al final del entrenamiento. Aquí realizamos un calentamiento lineal antes del decrecimiento del ritmo de aprendizaje (Linear Warmup With Linear Decay). La Table 5.1 enumera los parámetros de arquitectura que utilizamos en todos nuestros experimentos con Beto.
Parameter |
Value |
|---|---|
Transformer layers |
last |
Learning rate |
5e-6 |
Mini Batch size |
4 |
Max epochs |
150 |
Optimizer |
AdamW |
Scheduler |
Linear Warmup With Linear Decay |
Warmup |
0.1 |
Subword pooling |
first |
La Table 5.2 enumera los hiperparámetros utilizados para entrenar con de XLM RoBERTa Large. La única diferencia es el uso de una tasa de aprendizaje de 40 para XLM RoBERTa en lugar de 150 para BETO debido a la insuficiente memoria de la GPU.
Parameter |
Value |
|---|---|
Transformer layers |
last |
Learning rate |
5e-6 |
Mini Batch size |
4 |
Max epochs |
40 |
Optimizer |
AdamW |
Scheduler |
Linear Warmup With Linear Decay |
Warmup |
0.1 |
Subword pooling |
first |
5.2.2. Entrenamiento: Método basado en características#
La Fig. 5.4 ofrece una visión general del enfoque basado en características: Las representaciones de las palabras se extraen del transformador promediando todas las capas (all-layer-mean) o concatenando las representaciones de las cuatro últimas capas (last four-layers). A continuación, se introducen en una arquitectura LSTM-CRF estándar [Huang et al., 2015] como características. Volvemos a utilizar la estrategia de agrupación de subpalabras ilustrada en la Fig. 5.3.
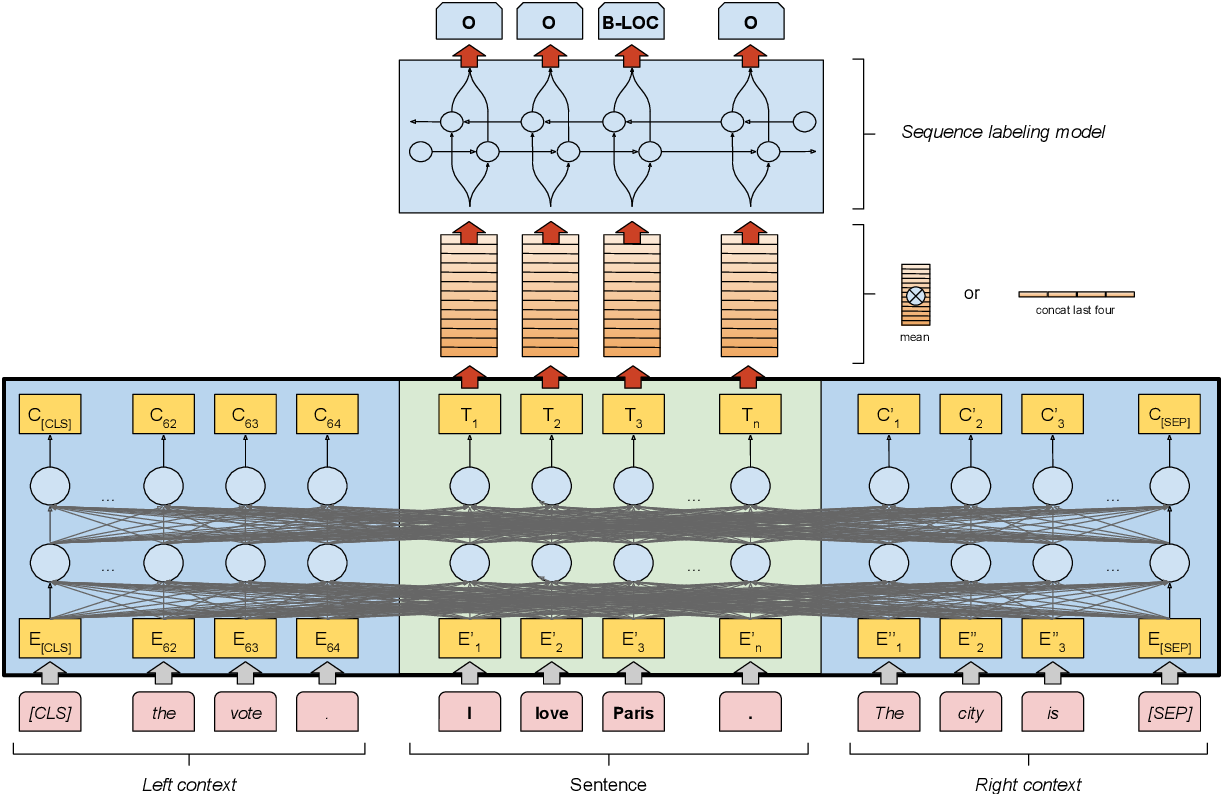
Fig. 5.4 Visión general del enfoque basado en características. La autoatención se calcula sobre todos los tokens de entrada (incluyendo el contexto izquierdo y derecho). contexto). La representación final de cada elemento de la frase (“I love Paris”, sombreada en verde) puede calcularse como a) media sobre todas las capas del modelo basado en transformadores o b) concatenando las cuatro últimas capas.#
En nuestros experimentos hemos elegido la primera variante, crear representaciones de las palabras promediando todas las capas (all-layer-mean).
5.2.2.1. Procedimiento de entrenamiento#
Adoptamos el procedimiento de entrenamiento estándar utilizado en trabajos anteriores. Entrenamos la red con SGD con una tasa de aprendizaje mayor que se rectifica con los datos de desarrollo. El entrenamiento finaliza cuando el ritmo de aprendizaje es demasiado pequeño. Los parámetros utilizados para entrenar un modelo basado en características se muestran en Table 5.3.
Parameter |
Value |
|---|---|
Transformer layers |
last |
Learning rate |
0.1 |
Mini Batch size |
4 |
Max epochs |
500 |
Optimizer |
SGD |
Scheduler |
Anneal On Plateau |
Subword pooling |
first |
5.2.2.2. Entrenamiento: Flair + LSTM-CRF#
La Fig. 5.5 ofrece una visión general del enfoque basado en características: Las representaciones de las palabras se extraen de modelos de idiomas. A continuación, se introducen en una arquitectura LSTM-CRF estándar [Huang et al., 2015] como características.
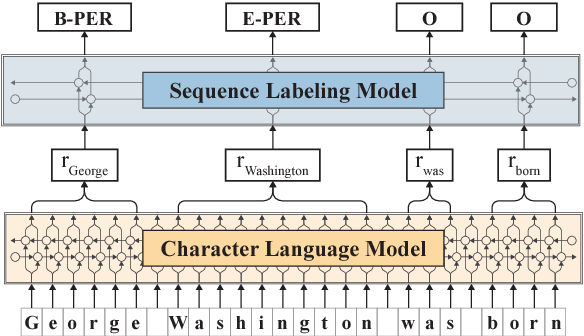
Fig. 5.5 Visión general del enfoque basado en características usando los embeddings contextuales de Flair [Akbik et al., 2018].#
5.2.2.3. Procedimiento de entrenamiento#
Procedemos exactamente como en el Método basado en características. Los parámetros utilizados para entrenar un modelo basado en características con Flair se muestran en Table 5.4.
Parameter |
Value |
|---|---|
Learning rate |
0.1 |
Mini Batch size |
4 |
Max epochs |
150 |
Optimizer |
SGD |
Scheduler |
Anneal On Plateau |
Note
Realizamos experimentos en una NVIDIA Quadro M6000 (24GB) para el ajuste fino y el enfoque basado en características. Informamos de los tiempos medios de entrenamiento de nuestras mejores configuraciones en la Tabla 5.7.
5.2.3. Numero de parámetros del modelo#
| FINETUNE | LSTM CRF | |||||||
|---|---|---|---|---|---|---|---|---|
| XLMR + WE | XLMR | BETO + WE | BETO | BETO | BETO + WE | FLAIR | FLAIR + WE | |
| Numero de parámetros en Million | 856 | 560 | 406 | 64 | 114 | 410 | 64 | 361 |
Fig. 5.6 Numero de parámetros contenido en cada unos de los modelos utilizados#
Podemos ver que los embeddings de menor a mayor son Flair, Beto y XLM RoBERTa Large. Los embeddings estáticos (WE) son en sí mismos muy grandes ya que tienen un vocabulario muy amplio. Por lo tanto, aumentan en gran medida el tamaño del modelo final. Por último, el uso de una red del tipo LSTM-CRF añade más parámetros que el uso de una simple proyección lineal sobre el espacio de soluciones.
5.2.4. Training time#
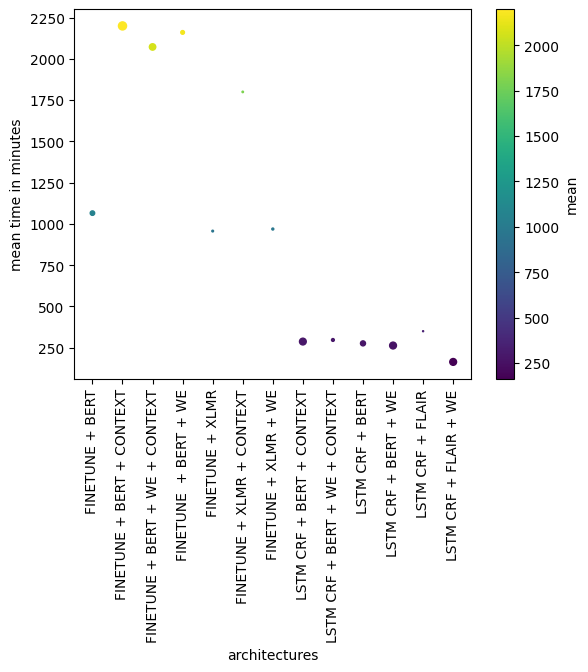
Fig. 5.7 Tiempo de entrenamiento por cada configuración. El punto es mas grande cuando la desviación estándar aumenta.#
Optar por la estrategia basada en el ajuste fino de un modelo de Transformers multiplica el tiempo de entrenamiento por 4 para el mismo número de iteraciones. Añadir un contexto, porque aumenta el número de tokens que el modelo tendrá que ingerir al mismo tiempo, hace que el entrenamiento sea aún más lento. Y, por último, el uso de modelos más grandes, como XLM RoBERTa Large, ralentiza aún más el entrenamiento.