El concepto de transfer learning en NLP
5.1. El concepto de transfer learning en NLP#
Hoy en día, es una práctica habitual en visión por ordenador consiste en utilizar el transfer learning para entrenar una red neuronal convolucional como ResNet en una tarea, y luego adaptarla o ajustarla en una nueva tarea. Esto permite a la red hacer uso de los conocimientos aprendidos en la tarea original. Desde el punto de vista de la arquitectura, esto implica dividir el modelo en un cuerpo y una cabeza, donde la cabeza es una red específica de la tarea. Durante el entrenamiento, los pesos del cuerpo aprenden características generales del dominio de origen, y estos pesos se utilizan para inicializar un nuevo modelo para la nueva tarea 1. En comparación con el aprendizaje supervisado tradicional, este enfoque suele producir modelos de alta calidad que pueden entrenarse de forma mucho más eficiente en una variedad de tareas posteriores, y con muchos menos datos etiquetados. En la Fig. 5.1 se muestra una comparación de los dos enfoques.
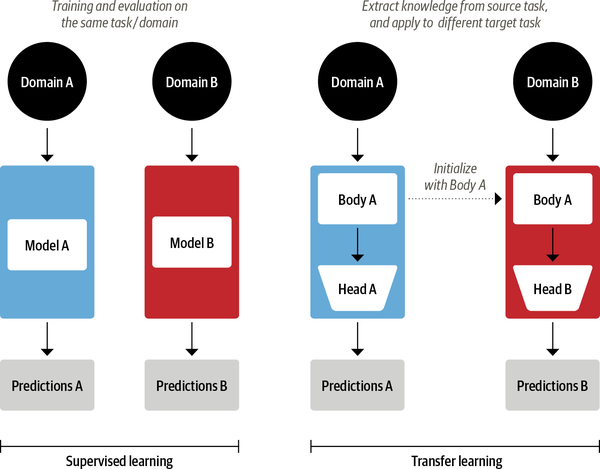
Fig. 5.1 Comparación entre el aprendizaje supervisado tradicional (izquierda) y el transfer learning (derecha)#
En la visión por ordenador, los modelos se entrenan primero en conjuntos de datos a gran escala, como ImageNet, que contienen millones de imágenes. Este proceso se denomina preentrenamiento y su principal objetivo es enseñar a los modelos las características básicas de las imágenes, como los bordes o los colores. A continuación, estos modelos pre-entrenados pueden afinarse en una tarea posterior, como la clasificación de especies florales, con un número relativamente pequeño de ejemplos etiquetados (normalmente unos cientos por clase). Los modelos perfeccionados suelen alcanzar una mayor precisión que los modelos supervisados entrenados desde cero con la misma cantidad de datos etiquetados.
Aunque el transfer learning se ha convertido en el enfoque estándar de la visión por ordenador, durante muchos años no estaba claro cuál era el proceso de preentrenamiento análogo para la PNL. En consecuencia, las aplicaciones de PNL solían requerir grandes cantidades de datos etiquetados para lograr un alto rendimiento. E incluso entonces, ese rendimiento no se comparaba con lo que se lograba en el dominio de la visión.
En 2017 y 2018, varios grupos de investigación propusieron nuevos enfoques que finalmente hicieron que el transfer learning funcionara para la PNL. Comenzó con una idea de los investigadores de OpenAI, que obtuvieron un fuerte rendimiento en una tarea de clasificación de sentimientos mediante el uso de características extraídas del preentrenamiento no supervisado [Radford et al., 2017]. A esto le siguió ULMFiT, que introdujo un marco general para adaptar los modelos LSTM pre-entrenados para diversas tareas 2.
Como se ilustra en la Fig. 5.2, ULMFiT consta de tres pasos principales:
- preentrenamiento
El objetivo inicial del entrenamiento es bastante sencillo: predecir la siguiente palabra basándose en las palabras anteriores. Esta tarea se denomina modelado del lenguaje. La elegancia de este enfoque reside en el hecho de que no se necesitan datos etiquetados, y se puede hacer uso de textos disponibles en abundancia en fuentes como Wikipedia 3.
- Adaptación de dominio
Una vez que el modelo lingüístico se ha pre-entrenado en un corpus a gran escala, el siguiente paso es adaptarlo al corpus del dominio (por ejemplo, de Wikipedia al corpus de críticas de cine de IMDb, como en la Fig. 5.2). En esta etapa se sigue utilizando el modelado del lenguaje, pero ahora el modelo tiene que predecir la siguiente palabra en el corpus de destino.
- Ajuste fino
En esta etapa, el modelo lingüístico se ajusta con una capa de clasificación para la tarea objetivo (por ejemplo, clasificar el sentimiento de las críticas de películas en la Fig. 5.2).
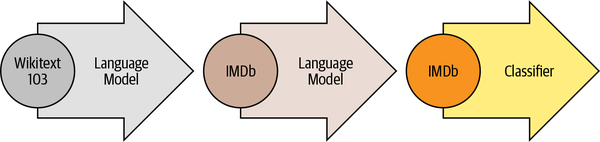
Fig. 5.2 El proceso ULMFiT (Taken from Jeremy Howard course)#
Al introducir un marco viable para el preentrenamiento y el transfer learning en PNL, ULMFiT proporcionó la pieza que faltaba para que los transformadores despegaran. En 2018, se lanzaron dos transformadores que combinaban la auto-atención con el transfer learning:
- GPT
Utiliza solo la parte del decodificador de la arquitectura del transformador, y el mismo enfoque de modelado del lenguaje que ULMFiT. GPT fue pre-entrenado en el BookCorpus [Zhu et al., 2015], que consiste en 7.000 libros inéditos de una variedad de géneros, incluyendo Aventura, Fantasía y Romance.
- BERT
Utiliza la parte del codificador de la arquitectura Transformer y una forma especial de modelado del lenguaje denominada modelado del lenguaje enmascarado. El objetivo del modelado del lenguaje enmascarado es predecir palabras enmascaradas al azar en un texto. Por ejemplo, dada una frase como “Miré mi [MASK] y vi que [MASK] llegaba tarde”, el modelo necesita predecir los candidatos más probables para las palabras enmascaradas que se denotan con [MASK]. BERT se pre-entrenó con el BookCorpus y la Wikipedia en inglés.
GPT y BERT establecieron un nuevo estado de la técnica en una variedad de puntos de referencia de PNL y marcaron el comienzo de la era de los transformadores.
- 1
Recordamos que los pesos son los parámetros que se pueden aprender de una red neuronal.
- 2
Un trabajo relacionado con esta época fue ELMo (Embeddings from Language Models), que mostró cómo el preentrenamiento de los LSTM podía producir embeddings de palabras de alta calidad para tareas posteriores.
- 3
Esto es más cierto en el caso del inglés que en el de la mayoría de las lenguas del mundo, donde puede ser difícil obtener un gran corpus de texto digitalizado. La búsqueda de formas de superar esta carencia es un área activa de la investigación y el activismo en PNL.