Transformers para NER
Contents
5.4. Transformers para NER#
Para dar una introducción práctica a los transformadores, exploraremos cómo un modelo de transformador llamado XLM-RoBERTa nos permite realizar esta tarea. Al igual que el BERT, este modelo utiliza la técnica del lenguaje enmascarado como objetivo de preentrenamiento, pero se entrena conjuntamente con textos en más de cien idiomas. Gracias al preentrenamiento en enormes corpus de muchas lenguas, estos transformadores multilingües permiten la transferencia multilingüe sin necesidad de hornear. Esto significa que un modelo perfeccionado en una lengua puede aplicarse a otras lenguas sin necesidad de formación adicional. Aunque no es nuestro objetivo en esta sección, sería interesante probarlo en nuestros datos jurídicos multilingües, especialmente en los datos catalanes. Además, este es el modelo utilizado por los autores de Flert [Schweter and Akbik, 2020] y tenemos resultados para él en 3 de las configuraciones probadas.
5.4.1. Dataset#
import codecs
from dataclasses import asdict, dataclass, field
from typing import DefaultDict, List
from datasets import ClassLabel, Dataset, DatasetDict, Features, Sequence, Value
from spacy.tokens import Token
from meddocan.data import ArchiveFolder
from meddocan.data.docs_iterators import GsDocs
@dataclass
class Rows:
origin: List[str] = field(default_factory=list)
text: List[str] = field(default_factory=list)
input_ids: List[str] = field(default_factory=list)
tokens: List[List[str]] = field(default_factory=list)
ner_tags: List[List[str]] = field(default_factory=list)
def get_tok_tag(token: Token) -> str:
if (tag := token.ent_iob_) in ["", "O"]:
tag = "O"
else:
tag = f"{tag}-{token.ent_type_}"
text = token.text
if text[0].encode("utf-8") == codecs.BOM_UTF8:
# Remove the detected BOOM.
# If not removed, the sign sometimes appears in
# documents in BIO format opened by vscode.
text = text[1:]
return text, tag
def meddocan(folder: str = None) -> Dataset:
archives = (ArchiveFolder.train, ArchiveFolder.dev, ArchiveFolder.test)
label_count = DefaultDict(int)
dataset_dict = DefaultDict(Dataset)
store_rows = DefaultDict(Rows)
for archive in archives:
brat_docs = GsDocs(archive)
rows = Rows()
input_ids = 0
for brat_doc in brat_docs:
for sent in brat_doc.doc.sents:
# Read text and corresponding tag -> TOKEN, IOB
tokens, iobs = zip(*map(get_tok_tag, sent))
if not tokens[-1].strip(): # Remove "\n" tokens
tokens, iobs = tokens[:-1], iobs[:-1]
for iob in iobs:
label_count[iob] += 1
input_ids += 1
# Get index of the key in label_count
llc = list(label_count)
idx = list(map(llc.index, iobs))
# Fill Rows Dataclass
rows.origin.append(brat_doc.brat_files_pair.txt.at)
rows.text.append(sent.text.strip())
rows.input_ids.append(input_ids)
rows.tokens.append(tokens)
rows.ner_tags.append(idx)
store_rows[archive.value] = rows
features = Features(
{
"origin": Value("string"),
"text": Value("string"),
"input_ids": Value("int32"),
"tokens": Sequence(Value("string")),
"ner_tags": Sequence(
ClassLabel(names=list(label_count.keys()))
),
}
)
for archive in archives:
dataset_dict[archive.value] = Dataset.from_dict(
asdict(store_rows[archive.value]), features, split=archive.value
)
# Construct the DatasetDict
return DatasetDict(dataset_dict)
ds = meddocan()
Utilizamos la función meddocan() para crear una instancia de datasets.DatasetDict llamada ds. Nuestro diccionario de conjunto de datos está compuesto de 3 datasets.Dataset, el de entrenamiento, de validación y de test.
for split in ds.keys():
ds[split] = ds[split].shuffle(seed=0)
Aquí utilizamos el método shuffle para evitar un sesgue accidental en los datos.
Veamos cuántos ejemplos o frases tenemos por cada dataset accediendo al atributo Dataset.num_rows:
import pandas as pd
pd.DataFrame({k: v.num_rows for k, v in ds.items()}, index=["number of example per split"])
| train | dev | test | |
|---|---|---|---|
| number of example per split | 10312 | 5268 | 5155 |
Veamos un ejemplo extraído del conjunto de datos
pd.DataFrame(ds["train"][11:12], index=["Sentence"]).T
| Sentence | |
|---|---|
| origin | train/brat/S0212-71992006000800008-1.txt |
| text | NASS: 99 00154744 02. |
| input_ids | 3651 |
| tokens | [NASS, :, 99, 00154744, 02, .] |
| ner_tags | [0, 0, 4, 5, 5, 0] |
En nuestros objetos Dataset, las claves de nuestro ejemplo corresponden a los nombres de las columnas de una tabla Arrow 4, mientras que los valores denotan las entradas de cada columna. En particular, vemos que la columna ner_tags corresponde a la asignación de cada entidad a un ID de clase. Esto es un poco críptico para el ojo humano, así que vamos a crear una nueva columna con las conocidas etiquetas. Para ello, lo primero que hay que observar es que nuestro objeto Dataset tiene un atributo features que especifica los tipos de datos subyacentes asociados a cada columna:
for k, v in ds["train"].features.items():
print(f"{k}: {v}")
origin: Value(dtype='string', id=None)
text: Value(dtype='string', id=None)
input_ids: Value(dtype='int32', id=None)
tokens: Sequence(feature=Value(dtype='string', id=None), length=-1, id=None)
ner_tags: Sequence(feature=ClassLabel(num_classes=45, names=['O', 'B-NOMBRE_SUJETO_ASISTENCIA', 'I-NOMBRE_SUJETO_ASISTENCIA', 'B-ID_SUJETO_ASISTENCIA', 'B-ID_ASEGURAMIENTO', 'I-ID_ASEGURAMIENTO', 'B-CALLE', 'I-CALLE', 'B-TERRITORIO', 'B-FECHAS', 'I-FECHAS', 'B-PAIS', 'B-EDAD_SUJETO_ASISTENCIA', 'I-EDAD_SUJETO_ASISTENCIA', 'B-SEXO_SUJETO_ASISTENCIA', 'B-NOMBRE_PERSONAL_SANITARIO', 'I-NOMBRE_PERSONAL_SANITARIO', 'B-ID_TITULACION_PERSONAL_SANITARIO', 'I-ID_TITULACION_PERSONAL_SANITARIO', 'B-CORREO_ELECTRONICO', 'I-CORREO_ELECTRONICO', 'B-HOSPITAL', 'I-HOSPITAL', 'B-FAMILIARES_SUJETO_ASISTENCIA', 'I-FAMILIARES_SUJETO_ASISTENCIA', 'I-TERRITORIO', 'B-OTROS_SUJETO_ASISTENCIA', 'B-INSTITUCION', 'I-INSTITUCION', 'I-PAIS', 'B-NUMERO_TELEFONO', 'I-NUMERO_TELEFONO', 'B-ID_CONTACTO_ASISTENCIAL', 'B-NUMERO_FAX', 'I-NUMERO_FAX', 'B-CENTRO_SALUD', 'I-CENTRO_SALUD', 'I-ID_SUJETO_ASISTENCIA', 'I-OTROS_SUJETO_ASISTENCIA', 'B-PROFESION', 'I-PROFESION', 'I-SEXO_SUJETO_ASISTENCIA', 'B-ID_EMPLEO_PERSONAL_SANITARIO', 'I-ID_EMPLEO_PERSONAL_SANITARIO', 'I-ID_CONTACTO_ASISTENCIAL'], id=None), length=-1, id=None)
La clase Sequence especifica que el campo contiene una lista de características, que en el caso de ner_tags corresponde a una lista de características ClassLabel. Seleccionemos esta característica del conjunto de entrenamiento de la siguiente manera:
tags = ds["train"].features["ner_tags"].feature
print(tags)
ClassLabel(num_classes=45, names=['O', 'B-NOMBRE_SUJETO_ASISTENCIA', 'I-NOMBRE_SUJETO_ASISTENCIA', 'B-ID_SUJETO_ASISTENCIA', 'B-ID_ASEGURAMIENTO', 'I-ID_ASEGURAMIENTO', 'B-CALLE', 'I-CALLE', 'B-TERRITORIO', 'B-FECHAS', 'I-FECHAS', 'B-PAIS', 'B-EDAD_SUJETO_ASISTENCIA', 'I-EDAD_SUJETO_ASISTENCIA', 'B-SEXO_SUJETO_ASISTENCIA', 'B-NOMBRE_PERSONAL_SANITARIO', 'I-NOMBRE_PERSONAL_SANITARIO', 'B-ID_TITULACION_PERSONAL_SANITARIO', 'I-ID_TITULACION_PERSONAL_SANITARIO', 'B-CORREO_ELECTRONICO', 'I-CORREO_ELECTRONICO', 'B-HOSPITAL', 'I-HOSPITAL', 'B-FAMILIARES_SUJETO_ASISTENCIA', 'I-FAMILIARES_SUJETO_ASISTENCIA', 'I-TERRITORIO', 'B-OTROS_SUJETO_ASISTENCIA', 'B-INSTITUCION', 'I-INSTITUCION', 'I-PAIS', 'B-NUMERO_TELEFONO', 'I-NUMERO_TELEFONO', 'B-ID_CONTACTO_ASISTENCIAL', 'B-NUMERO_FAX', 'I-NUMERO_FAX', 'B-CENTRO_SALUD', 'I-CENTRO_SALUD', 'I-ID_SUJETO_ASISTENCIA', 'I-OTROS_SUJETO_ASISTENCIA', 'B-PROFESION', 'I-PROFESION', 'I-SEXO_SUJETO_ASISTENCIA', 'B-ID_EMPLEO_PERSONAL_SANITARIO', 'I-ID_EMPLEO_PERSONAL_SANITARIO', 'I-ID_CONTACTO_ASISTENCIAL'], id=None)
Podemos utilizar el método ClassLabel.int2str() para crear una nueva columna en nuestro conjunto de entrenamiento con nombres de clases para cada etiqueta. Usaremos el método map() para devolver un dict con la clave correspondiente al nuevo nombre de la columna y el valor como una lista de nombres de clases:
def create_tag_names(batch):
return {"ner_tags_str": [tags.int2str(idx) for idx in batch["ner_tags"]]}
ds = ds.map(create_tag_names)
Ahora que tenemos nuestras etiquetas en formato legible para el ser humano, veamos cómo se alinean los tokens y las etiquetas para el primer ejemplo del conjunto de entrenamiento:
ds_example = ds["train"][12]
pd.DataFrame([ds_example["tokens"], ds_example["ner_tags_str"]], ["Tokens", "Tags"])
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |
|---|---|---|---|---|---|---|---|---|---|---|
| Tokens | Fecha | de | nacimiento | : | 01 | / | 01 | / | 1987 | . |
| Tags | O | O | O | O | B-FECHAS | I-FECHAS | I-FECHAS | I-FECHAS | I-FECHAS | O |
Como comprobación rápida de que no tenemos ningún desequilibrio inusual en las etiquetas, calculemos las frecuencias de cada entidad en cada división:
from collections import Counter
split2freqs = DefaultDict(Counter)
for split, dataset in ds.items():
for row in dataset["ner_tags_str"]:
for tag in row:
if tag.startswith("B"):
tag_type = tag.split("-")[1]
split2freqs[split][tag_type] += 1
class_freq = pd.DataFrame.from_dict(split2freqs, orient="index").fillna(0)
class_freq.T
| train | dev | test | |
|---|---|---|---|
| ID_CONTACTO_ASISTENCIAL | 77.0 | 32.0 | 39.0 |
| PAIS | 713.0 | 347.0 | 363.0 |
| FECHAS | 1231.0 | 724.0 | 611.0 |
| NOMBRE_PERSONAL_SANITARIO | 1000.0 | 497.0 | 501.0 |
| INSTITUCION | 98.0 | 72.0 | 67.0 |
| CALLE | 862.0 | 434.0 | 413.0 |
| TERRITORIO | 1875.0 | 987.0 | 956.0 |
| CORREO_ELECTRONICO | 469.0 | 241.0 | 249.0 |
| EDAD_SUJETO_ASISTENCIA | 1035.0 | 521.0 | 518.0 |
| SEXO_SUJETO_ASISTENCIA | 925.0 | 455.0 | 461.0 |
| ID_ASEGURAMIENTO | 391.0 | 194.0 | 198.0 |
| NOMBRE_SUJETO_ASISTENCIA | 1009.0 | 503.0 | 502.0 |
| ID_TITULACION_PERSONAL_SANITARIO | 471.0 | 226.0 | 234.0 |
| ID_SUJETO_ASISTENCIA | 567.0 | 292.0 | 283.0 |
| HOSPITAL | 255.0 | 140.0 | 130.0 |
| FAMILIARES_SUJETO_ASISTENCIA | 243.0 | 92.0 | 81.0 |
| PROFESION | 24.0 | 4.0 | 9.0 |
| CENTRO_SALUD | 6.0 | 2.0 | 6.0 |
| NUMERO_TELEFONO | 58.0 | 25.0 | 26.0 |
| NUMERO_FAX | 15.0 | 6.0 | 7.0 |
| OTROS_SUJETO_ASISTENCIA | 9.0 | 6.0 | 7.0 |
| ID_EMPLEO_PERSONAL_SANITARIO | 0.0 | 1.0 | 0.0 |
Esto tiene buena pinta: las distribuciones de las frecuencias de nuestras etiquetas son más o menos las mismas para cada división, por lo que los conjuntos de validación y prueba deberían proporcionar una buena medida de la capacidad de generalización de nuestro etiquetador NER. A continuación, vamos a ver algunos transformadores multilingües populares y cómo se pueden adaptar para abordar nuestra tarea NER.
5.4.2. Transformadores multi-idiomas#
Los transformadores multilingües tienen arquitecturas y procedimientos de entrenamiento similares a los de sus homólogos monolingües, con la salvedad de que el corpus utilizado para el preentrenamiento consta de documentos en muchos idiomas. Una característica notable de este enfoque es que, a pesar de no recibir información explícita para diferenciar entre las lenguas, las representaciones lingüísticas resultantes son capaces de generalizar bien entre las lenguas para una variedad de tareas posteriores. En algunos casos, esta capacidad de transferencia entre lenguas puede producir resultados que compiten con los de los modelos monolingües, lo que evita la necesidad de entrenar un modelo por lengua.
Para medir el progreso de la transferencia multilingüe para la NER, se suelen utilizar los conjuntos de datos CoNLL-2002 y CoNLL-2003 como referencia para el inglés, el holandés, el español y el alemán. Esta referencia consiste en artículos de noticias anotados con las categorías LOC, PER y ORG que son diferentes de las categorías de MEDDOCAN. Los modelos de transformadores multilingües suelen evaluarse de tres maneras diferentes:
- en
Se ajustan a los datos de entrenamiento en inglés y luego se evalúan en el conjunto de pruebas de cada idioma. En el caso de nuestros datos jurídicos se podría ajustar sobre nuestros datos en castellano y evaluar sobre nuestros datos en catalán.
- Cada uno de ellos
Se ajustan y evalúan en datos de prueba monolingües para medir el rendimiento por idioma.
- Todos
Ajuste fino en todos los datos de entrenamiento para evaluar en todos los conjuntos de prueba de cada idioma.
En nuestra tarea NER solo nos centraremos en la primera parte. Uno de los primeros transformadores multilingües fue mBERT, que utiliza la misma arquitectura y el mismo objetivo de preentrenamiento que BERT, pero añade artículos de Wikipedia de muchos idiomas al corpus de preentrenamiento. Desde entonces, mBERT ha sido sustituido por XLM-RoBERTa (o XLM-R para abreviar), por lo que ese es el modelo que consideraremos en este capítulo.
XLM-R sólo utiliza MLM (Masked Language Model) como objetivo de preentrenamiento para 100 idiomas, pero se distingue por el enorme tamaño de su corpus de preentrenamiento en comparación con sus predecesores: Volcados de Wikipedia para cada idioma y 2,5 terabytes de datos de Common Crawl de la web. Este corpus es varios órdenes de magnitud más grande que los utilizados en modelos anteriores y proporciona un aumento significativo de la señal para las lenguas con pocos recursos, como el birmano y el suajili, donde sólo existe un pequeño número de artículos de Wikipedia.
La parte RoBERTa [Liu et al., 2019] del nombre del modelo hace referencia al hecho de que el enfoque de preentrenamiento es el mismo que el de los modelos monolingües RoBERTa. Los desarrolladores de RoBERTa mejoraron varios aspectos de BERT, en particular eliminando por completo la tarea de predicción de la siguiente frase. XLM-R también abandona los embeddings lingüísticos utilizados en XLM y utiliza SentencePiece [Kudo and Richardson, 2018] para tokenizar los textos en bruto directamente. Además de su naturaleza multilingüe, una diferencia notable entre XLM-R y RoBERTa es el tamaño de los respectivos vocabularios: ¡250.000 tokens frente a 55.000!
XLM-R es una gran opción para las tareas de NLU multilingüe. En la siguiente sección, exploraremos cómo puede tokenizar eficientemente en castellano.
5.4.3. Una mirada más cercana a la tokenización#
En lugar de utilizar un tokenizador de WordPiece, XLM-R utiliza un tokenizador llamado SentencePiece que está entrenado en el texto original de los cien idiomas. Para ver cómo se compara SentencePiece con WordPiece, carguemos los tokenizadores BERT para el castellano y XLM-R de la forma habitual con HuggingFace Transformers:
from transformers import AutoTokenizer
bert_model_name = "dccuchile/bert-base-spanish-wwm-cased"
xlmr_model_name = "xlm-roberta-large"
bert_tokenizer = AutoTokenizer.from_pretrained(bert_model_name)
xlmr_tokenizer = AutoTokenizer.from_pretrained(xlmr_model_name)
Al codificar una pequeña secuencia de texto también podemos recuperar los tokens especiales que cada modelo utilizó durante el preentrenamiento:
text = "Jack Sparrow ama Nueva York!"
bert_tokens = bert_tokenizer(text).tokens()
xlmr_tokens = xlmr_tokenizer(text).tokens()
pd.DataFrame([bert_tokens, xlmr_tokens], ["BERT", "XLM-R"])
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| BERT | [CLS] | J | ##ac | ##k | Spar | ##ro | ##w | ama | Nueva | Yor | ##k | ! | [SEP] |
| XLM-R | <s> | ▁Jack | ▁Spar | row | ▁ama | ▁Nueva | ▁York | ! | </s> | None | None | None | None |
Aquí vemos que en lugar de los tokens [CLS] y [SEP] que BERT utiliza para las tareas de clasificación de frases, XLM-R utiliza <s> y <s> para denotar el comienzo y el final de una secuencia. Estos tokens se añaden en la etapa final de la tokenización, como veremos a continuación.
5.4.3.1. La tubería del tokenizador#
Hasta ahora hemos tratado la tokenización como una única operación que transforma las cadenas en enteros que podemos pasar por el modelo. Esto no es del todo exacto, y si echamos un vistazo más de cerca podemos ver que en realidad es una tubería de procesamiento completa que normalmente consta de cuatro pasos, como se muestra en la Fig. 5.8.

Fig. 5.8 Las etapas en la tubería de tokenización#
Veamos con más detalle cada paso del procesamiento e ilustremos su efecto con la frase de ejemplo “¡Jack Sparrow ama Nueva York!”:
- Normalización
Este paso corresponde al conjunto de operaciones que se aplican a una cadena sin procesar para hacerla más “limpia”. Las operaciones más comunes son la eliminación de los espacios en blanco y de los caracteres acentuados. La normalización Unicode es otra operación de normalización común que aplican muchos tokenizadores para hacer frente al hecho de que a menudo existen varias formas de escribir el mismo carácter. Esto puede hacer que dos versiones de la “misma” cadena (es decir, con la misma secuencia de caracteres abstractos) parezcan diferentes; los esquemas de normalización Unicode como NFC, NFD, NFKC y NFKD sustituyen las diversas formas de escribir el mismo carácter por formas estándar. Otro ejemplo de normalización es el de las minúsculas. Si se espera que el modelo sólo acepte y utilice caracteres en minúsculas, esta técnica puede utilizarse para reducir el tamaño del vocabulario que requiere. Después de la normalización, nuestra cadena de ejemplo se vería como “¡Jack Sparrow ama Nueva York!”.
Note
En le caso del corpus Meddocan, hemos quitado los espacios así como los saltos a la linea a la hora de entrenar el modelo con Flair.
- Pretokenización
Este paso divide un texto en objetos más pequeños que dan un límite superior a lo que serán sus tokens al final del entrenamiento (Es la tarea de la cual se encargar el
meddocan.language.pipeline.meddocan_pipeline. Una buena manera de pensar en esto es que el pretokenizador dividirá el texto en “palabras”, y los tokens finales serán partes de esas palabras. En los idiomas que lo permiten (el inglés, el alemán y muchos idiomas indoeuropeos), las cadenas pueden dividirse en palabras a partir de los espacios en blanco y la puntuación. Por ejemplo, este paso podría transformar nuestras [“Jack”, “Sparrow”, “ama”, “Nueva”, “York”, “!”]. A continuación, estas palabras son más sencillas de dividir en subpalabras con los algoritmos Byte-Pair Encoding (BPE) o Unigram en el siguiente paso de la cadena. Sin embargo, la división en “palabras” no siempre es una operación trivial y determinista, ni siquiera una operación que tenga sentido. Por ejemplo, en lenguas como el chino, el japonés o el coreano, la agrupación de símbolos en unidades semánticas como las palabras indoeuropeas puede ser una operación no determinista con varios grupos igualmente válidos. En este caso, podría ser mejor no pretokenizar el texto y, en su lugar, utilizar una biblioteca específica del idioma para la pretokenización.- Modelo de tokenización
Una vez normalizados y pre-tokenizados los textos de entrada, el tokenizador aplica un modelo de división de subpalabras a las palabras. Esta es la parte de la cadena de producción que debe ser entrenada en su corpus (o que ha sido entrenada si estamos utilizando un tokenizador pre-entrenado como en nuestro caso). La función del modelo es dividir las palabras en subpalabras para reducir el tamaño del vocabulario e intentar reducir el número de tokens fuera del vocabulario. Existen varios algoritmos de tokenización de subpalabras, como BPE, Unigram y WordPiece. Por ejemplo, nuestro ejemplo en marcha podría ser como [jack, spa, rrow, ama, new, york, !] después de aplicar el modelo de tokenización. Debemos tener en cuenta que en este punto ya no tenemos una lista de cadenas, sino una lista de enteros (IDs de entrada); para mantener el ejemplo ilustrativo, hemos mantenido las palabras pero hemos eliminado las comillas para indicar la transformación.
- Posprocesamiento
Este es el último paso del proceso de tokenización, en el que se pueden aplicar algunas transformaciones adicionales a la lista de tokens, por ejemplo, añadiendo tokens especiales al principio o al final de la secuencia de índices de entrada. Por ejemplo, un tokenizador de estilo BERT añadiría tokens de clasificación y separadores: [CLS, jack, spa, rrow, ama, new, york, !, SEP]. Esta secuencia (recordemos que será una secuencia de enteros, no los tokens que se ven aquí) se puede introducir en el modelo.
Volviendo a nuestra comparación de XLM-R y BERT, ahora entendemos que SentencePiece añade <s> y <\s> en lugar de [CLS] y [SEP] en el paso de posprocesamiento (como convención, seguiremos usando [CLS] y [SEP] en las ilustraciones gráficas). Volvamos al tokenizador SentencePiece para ver qué lo hace especial.
5.4.3.2. El Tokenizador SentencePiece#
El tokenizador de SentencePiece se basa en un tipo de segmentación de subpalabras llamado Unigram y codifica cada texto de entrada como una secuencia de caracteres Unicode. Esta última característica es especialmente útil para los corpus multilingües, ya que permite a SentencePiece ser agnóstico respecto a los acentos, la puntuación y el hecho de que muchos idiomas, como el japonés, no tienen caracteres de espacio en blanco. Otra característica especial de SentencePiece es que a los espacios en blanco se les asigna el símbolo Unicode U+2581, o el carácter ▁, también llamado carácter de cuarto de bloque inferior. Esto permite a SentencePiece destokenizar una secuencia sin ambigüedades y sin depender de pretokenizadores específicos del idioma. En nuestro ejemplo de la sección anterior, por ejemplo, podemos ver que WordPiece ha perdido la información de que no hay espacios en blanco entre “York” y “!”. Por el contrario, SentencePiece conserva los espacios en blanco en el texto tokenizado, de modo que podemos volver a convertirlo en texto crudo sin ambigüedades:
"".join(xlmr_tokens).replace(u"\u2581", " ")
'<s> Jack Sparrow ama Nueva York!</s>'
Ahora que entendemos cómo funciona SentencePiece, vamos a ver cómo podemos codificar nuestro sencillo ejemplo en una forma adecuada para NER. Lo primero que hay que hacer es cargar el modelo preentrenado con una cabeza de clasificación de tokens. Pero en lugar de cargar esta cabeza directamente desde HuggingFace Transformers, ¡la construiremos nosotros mismos! Profundizando en la API de HuggingFace Transformers, podemos hacer esto con sólo unos pocos pasos.
5.4.4. Transformadores para el NER#
Aquí presentamos el modelo de transformador lineal. Cuando se utiliza BERT y otros transformadores de sólo codificación la representación de cada token de entrada individual se introduce en la una capa totalmente conectada para dar salida a la entidad del token. Por este motivo, la NER se suele plantear como una tarea de clasificación de tokens. El proceso se parece al diagrama de la Figura Fig. 5.9.
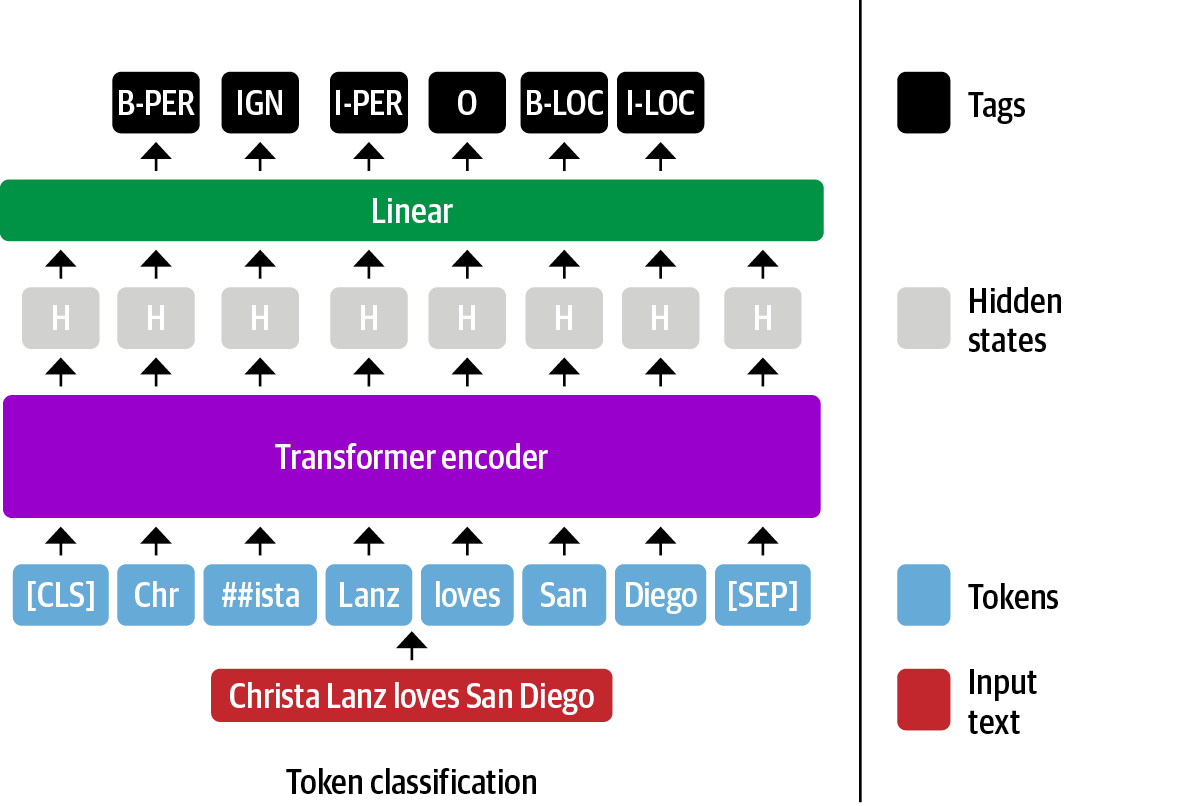
Fig. 5.9 Ajuste de un transformador basado en un codificador para el reconocimiento de entidades con nombre#
Hasta aquí todo bien, pero ¿cómo debemos tratar las subpalabras en una tarea de clasificación de tokens? Por ejemplo, el nombre “Christa” de la figura Fig. 5.9 está tokenizado en las subpalabras “Chr” y “##ista”, así que ¿a cuál(es) debe asignarse la etiqueta B-PER?
En el documento del BERT [Devlin et al., 2019], los autores asignaron esta etiqueta a la primera subpalabra (“Chr” en nuestro ejemplo) e ignoraron la siguiente (“##ista”). Esta es la convención que adoptaremos aquí, e indicaremos las subpalabras ignoradas con IGN. Posteriormente, podemos propagar fácilmente la etiqueta predicha de la primera subpalabra a las subpalabras siguientes en el paso de posprocesamiento. También podríamos haber optado por incluir la representación de la subpalabra “##ista” asignándole una copia de la etiqueta B-LOC, pero esto viola el formato IOB2.
Afortunadamente, todos los aspectos de la arquitectura que hemos visto en BERT se trasladan a XLM-R, ya que su arquitectura se basa en RoBERTa, ¡que es idéntica a BERT!
5.4.5. La anatomía del modelo de clase de Transformers#
Transformers está organizada en torno a clases dedicadas a cada arquitectura y tarea. Las clases del modelo asociadas a las diferentes tareas se nombran según la convención <NombreDelModelo>For<Tarea>, o AutoModelFor<Tarea> cuando se utilizan las clases AutoModel.
Para profundizar en la API de la libaría Transformers, vamos a ampliar el modelo existente para resolver nuestro problema de NLP. Podemos cargar los pesos de los modelos pre-entrenados y tenemos acceso a funciones de ayuda específicas para cada tarea. Esto nos permite construir modelos personalizados para objetivos específicos con muy poca sobrecarga. En esta sección, veremos cómo podemos implementar nuestro propio modelo personalizado.
5.4.5.1. Cuerpo y cabeza#
El concepto principal que hace que los transformers sean tan versátiles es la división de la arquitectura en un cuerpo y una cabeza. Ya hemos visto Section 5.1 que cuando pasamos de la tarea de preentrenamiento a la tarea posterior, tenemos que sustituir la última capa del modelo por una que sea adecuada para la tarea. Esta última capa se llama cabeza del modelo; es la parte que es específica de la tarea. El resto del modelo se denomina cuerpo, e incluye las capas de embeddings de tokens y de transformación que son independientes de la tarea. Esta estructura se refleja también en el código de la librería Transformers: el cuerpo de un modelo se implementa en una clase como BertModel o GPT2Model que devuelve los estados ocultos de la última capa. Los modelos específicos de tareas como BertForMaskedLM o BertForSequenceClassification utilizan el modelo base y añaden la cabeza necesaria sobre los estados ocultos, como se muestra en la Figura Fig. 5.10.
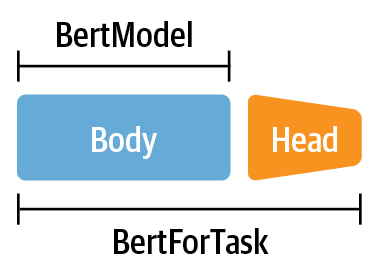
Fig. 5.10 La clase BertModel sólo contiene el cuerpo del modelo, mientras que las clases BertFor<Task> combinan el cuerpo con una cabeza dedicada a una tarea determinada#
Como vamos a ver a continuación, esta separación de cuerpos y cabezas nos permite construir una cabeza personalizada para cualquier tarea y simplemente montarla sobre un modelo pre-entrenado.
5.4.5.2. Crear un ModeloPersonalizado para la Clasificación de Tokens#
Hagamos el ejercicio de construir un cabezal de clasificación de tokens personalizado para XLM-R. Dado que XLM-R utiliza la misma arquitectura de modelo que RoBERTa, utilizaremos RoBERTa como modelo base, pero aumentado con ajustes específicos para XLM-R. Tenga en cuenta que este es un ejercicio educativo para mostrarle cómo construir un modelo personalizado que se podría modificar fácilmente. Para la clasificación de tokens, ya existe una clase XLMRobertaForTokenClassification que se puede importar desde huggingface Transformers.
Para empezar, necesitamos una estructura de datos que represente nuestro etiquetador XLM-R NER. Como primera aproximación, necesitaremos un objeto de configuración para inicializar el modelo y una función forward() para generar las salidas. Sigamos adelante y construyamos nuestra clase XLM-R para la clasificación de tokens:
import torch.nn as nn
from transformers import XLMRobertaConfig
from transformers.modeling_outputs import TokenClassifierOutput
from transformers.models.roberta.modeling_roberta import RobertaModel
from transformers.models.roberta.modeling_roberta import RobertaPreTrainedModel
class XLMRobertaForTokenClassification(RobertaPreTrainedModel):
config_class = XLMRobertaConfig
def __init__(self, config):
super().__init__(config)
self.num_labels = config.num_labels
# Load model body
self.roberta = RobertaModel(config, add_pooling_layer=False)
# Set up token classification head
self.dropout = nn.Dropout(config.hidden_dropout_prob)
self.classifier = nn.Linear(config.hidden_size, config.num_labels)
# Load and initialize weights
self.init_weights()
def forward(self, input_ids=None, attention_mask=None, token_type_ids=None,
labels=None, **kwargs):
# Use model body to get encoder representations
outputs = self.roberta(input_ids, attention_mask=attention_mask,
token_type_ids=token_type_ids, **kwargs)
# Apply classifier to encoder representation
sequence_output = self.dropout(outputs[0])
logits = self.classifier(sequence_output)
# Calculate losses
loss = None
if labels is not None:
loss_fct = nn.CrossEntropyLoss()
loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
# Return model output object
return TokenClassifierOutput(loss=loss, logits=logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions)
La config_class asegura que se usen los parámetros estándar de XLM-R cuando inicializamos un nuevo modelo. Si queremos cambiar los parámetros por defecto, podemos hacerlo sobrescribiendo los ajustes por defecto en la configuración. Con el método super() llamamos a la función de inicialización de la clase RobertaPreTrainedModel. Esta clase abstracta se encarga de la inicialización o carga de los pesos pre-entrenados. Luego cargamos el cuerpo de nuestro modelo, que es RobertaModel, y lo extendemos con nuestra propia cabeza de clasificación que consiste en un dropout y una capa feed-forward estándar. Hay que notar que establecemos add_pooling_layer=False para asegurarnos de que se devuelven todos los estados ocultos y no sólo el asociado al token [CLS]. Finalmente, inicializamos todos los pesos llamando al método init_weights() que heredamos de RobertaPreTrainedModel, que cargará los pesos pre-entrenados para el cuerpo del modelo e inicializará aleatoriamente los pesos de nuestra cabeza de clasificación de tokens.
Lo único que queda por hacer es definir lo que el modelo debe hacer en un pase hacia adelante con un método forward() como es de uso con Pytorch 5. Durante el pase hacia adelante, los datos son primero alimentados a través del cuerpo del modelo. Hay un número de variables de entrada, pero las únicas que necesitamos por ahora son input_ids y attention_mask. El estado oculto, que forma parte de la salida del cuerpo del modelo, se alimenta entonces a través de las capas de “dropout” y clasificación. Si también proporcionamos etiquetas en el pase forward, podemos calcular directamente la pérdida. Si hay una máscara de atención, tenemos que hacer un poco más de trabajo para asegurarnos de que sólo calculamos la pérdida de los tokens no enmascarados. Por último, envolvemos todas las salidas en un objeto TokenClassifierOutput que nos permite acceder a los elementos de una tupla.
Con sólo implementar dos funciones de una clase simple, podemos construir nuestro propio modelo de transformador personalizado. Y como heredamos de un PreTrainedModel, obtenemos instantáneamente acceso a todas las utilidades de huggingface Transformer, como from_pretrained(). Veamos cómo podemos cargar los pesos pre-entrenados en nuestro modelo personalizado.
5.4.5.3. Cargar un modelo personalizado#
Ahora estamos listos para cargar nuestro modelo de clasificación de tokens. Necesitaremos proporcionar alguna información adicional más allá del nombre del modelo, incluyendo las etiquetas que usaremos para etiquetar cada entidad y el mapeo de cada etiqueta a un ID y viceversa. Toda esta información puede derivarse de nuestra variable tags, que como objeto ClassLabel tiene un atributo names que podemos utilizar para derivar el mapeo:
index2tag = {idx: tag for idx, tag in enumerate(tags.names)}
tag2index = {tag: idx for idx, tag in enumerate(tags.names)}
Almacenaremos estos mapeos y el atributo tags.num_classes en el objeto AutoConfig. Pasar argumentos de palabras clave al método from_pretrained() anula los valores por defecto:
from transformers import AutoConfig
xlmr_config = AutoConfig.from_pretrained(xlmr_model_name,
num_labels=tags.num_classes,
id2label=index2tag, label2id=tag2index)
La clase AutoConfig contiene el plano de la arquitectura de un modelo. Cuando cargamos un modelo con AutoModel.from_pretrained(model_ckpt), el archivo de configuración asociado a ese modelo se descarga automáticamente. Sin embargo, si queremos modificar algo como el número de clases o los nombres de las etiquetas, podemos cargar primero la configuración con los parámetros que queremos personalizar.
Ahora, podemos cargar los pesos del modelo como siempre con la función from_pretrained() con el argumento adicional config. Hay que tener en cuenta que no hemos implementado la carga de pesos pre-entrenados en nuestra clase de modelo personalizada; la obtenemos gratuitamente al heredar de RobertaPreTrainedModel:
import torch
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
xlmr_model = (XLMRobertaForTokenClassification
.from_pretrained(xlmr_model_name, config=xlmr_config)
.to(device))
Como comprobación rápida de que hemos inicializado el tokenizador y el modelo correctamente, vamos a probar las predicciones en nuestra pequeña secuencia de entidades conocidas:
input_ids = xlmr_tokenizer.encode(text, return_tensors="pt")
pd.DataFrame([xlmr_tokens, input_ids[0].numpy()], index=["Tokens", "Input IDs"])
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
|---|---|---|---|---|---|---|---|---|---|
| Tokens | <s> | ▁Jack | ▁Spar | row | ▁ama | ▁Nueva | ▁York | ! | </s> |
| Input IDs | 0 | 21763 | 37456 | 15555 | 2527 | 111191 | 5753 | 38 | 2 |
Como se puede ver aquí, los tokens iniciales <s> y finales </s> reciben los IDs 0 y 2, respectivamente.
Por último, tenemos que pasar las entradas al modelo y extraer las predicciones tomando el argmax para obtener la clase más probable por token:
outputs = xlmr_model(input_ids.to(device)).logits
predictions = torch.argmax(outputs, dim=2)
print(f"Número de tokens en la secuencia: {len(xlmr_tokens)}")
print(f"Forma de la salida: {outputs.shape}")
Número de tokens en la secuencia: 9
Forma de la salida: torch.Size([1, 9, 45])
Aquí vemos que los logits tienen la forma [batch_size, num_tokens, num_tags], y que a cada token se le asigna un logit entre las 42 posibles etiquetas NER. Al enumerar sobre la secuencia, podemos ver rápidamente lo que predice el modelo pre-entrenado:
preds = [tags.names[p] for p in predictions[0].cpu().numpy()]
pd.DataFrame([xlmr_tokens, preds], index=["Tokens", "Tags"]).T
| Tokens | Tags | |
|---|---|---|
| 0 | <s> | B-FAMILIARES_SUJETO_ASISTENCIA |
| 1 | ▁Jack | B-CORREO_ELECTRONICO |
| 2 | ▁Spar | B-OTROS_SUJETO_ASISTENCIA |
| 3 | row | B-OTROS_SUJETO_ASISTENCIA |
| 4 | ▁ama | B-OTROS_SUJETO_ASISTENCIA |
| 5 | ▁Nueva | B-OTROS_SUJETO_ASISTENCIA |
| 6 | ▁York | B-OTROS_SUJETO_ASISTENCIA |
| 7 | ! | B-OTROS_SUJETO_ASISTENCIA |
| 8 | </s> | B-OTROS_SUJETO_ASISTENCIA |
No es de extrañar que nuestra capa de clasificación de tokens con pesos aleatorios deje mucho que desear; ¡afinemos con algunos datos etiquetados para mejorarla! Antes de hacerlo, vamos a envolver los pasos anteriores en una función de ayuda para su uso posterior:
def tag_text(text, tags, model, tokenizer):
# Get tokens with speecial characters
tokens = tokenizer(text).tokens()
# Encode the sequence into IDs
input_ids = tokenizer(text, return_tensors="pt").input_ids.to(device)
# Get predictions as distribution over 45 possible classes
outputs = model(input_ids)[0]
# Take argmax to get most likely class per token
predictions = torch.argmax(outputs, dim=2)
# Convert to DataFrame
preds = [tags.names[p] for p in predictions[0].cpu().numpy()]
return pd.DataFrame([tokens, preds], index=["Tokens", "Tags"])
Antes de poder entrenar el modelo, también necesitamos tokenizar las entradas y preparar las etiquetas. Lo haremos a continuación.
5.4.6. Tokenizar Textos para el NER#
Ahora que hemos establecido que el tokenizador y el modelo pueden codificar un solo ejemplo, nuestro siguiente paso es tokenizar todo el conjunto de datos para poder pasarlo al modelo XLM-R para su ajuste. HuggingFace Datasets proporciona una forma rápida de tokenizar un objeto Dataset con la operación map(). Para ello, recordemos que primero tenemos que definir una función con la firma mínima:
function(examples: Dict[str, List]) -> Dict[str, List]
donde ejemplos equivale a una porción de un Conjunto de datos, por ejemplo, ds['train'][:10]. Dado que el tokenizador XLM-R devuelve los IDs de entrada para las entradas del modelo, sólo tenemos que aumentar esta información con la máscara de atención y los IDs de las etiquetas que codifican la información sobre qué token está asociado a cada etiqueta NER.
Siguiendo el enfoque adoptado en la documentación de HuggingFace Transformers, veamos cómo funciona esto con nuestro único ejemplo de Meddocan, recogiendo primero las palabras y las etiquetas como listas normales:
words, label = ds_example["tokens"], ds_example["ner_tags"]
A continuación, se tokeniza cada palabra y se utiliza el argumento is_split_into_words para indicar al tokenizador que nuestra secuencia de entrada ya ha sido dividida en palabras:
tokenized_input = xlmr_tokenizer(words, is_split_into_words=True)
tokens = xlmr_tokenizer.convert_ids_to_tokens(tokenized_input["input_ids"])
pd.DataFrame([tokens], index=["Tokens"])
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Tokens | <s> | ▁Fe | cha | ▁de | ▁na | cimiento | ▁: | ▁01 | ▁/ | ▁01 | ▁/ | ▁1987 | ▁ | . | </s> |
En este ejemplo podemos ver que el tokenizador ha dividido “Fecha” en dos subpalabras, “▁Fe” y “cha”. Como seguimos la convención de que sólo “▁Fe” debe asociarse a la etiqueta B-FECHAS, necesitamos una forma de enmascarar las representaciones de las subpalabras después de la primera subpalabra. Afortunadamente, tokenized_input es una clase que contiene una función word_ids() que puede ayudarnos a conseguirlo:
words_id = tokenized_input.word_ids()
pd.DataFrame([tokens, words_id], index=["Tokens", "Word IDs"])
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Tokens | <s> | ▁Fe | cha | ▁de | ▁na | cimiento | ▁: | ▁01 | ▁/ | ▁01 | ▁/ | ▁1987 | ▁ | . | </s> |
| Word IDs | None | 0 | 0 | 1 | 2 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 9 | None |
Aquí podemos ver que word_ids ha asignado a cada subpalabra el índice correspondiente en la secuencia de palabras, por lo que a la primera subpalabra, “▁Fe”, se le asigna el índice 0, mientras que a “cha” se le asigna el índice 1 (ya que “cha” es la segunda palabra en palabras). También podemos ver que los tokens especiales como <s> y <s> se asignan a None. Fijemos -100 como etiqueta para estos tokens especiales y las subpalabras que deseamos enmascarar durante el entrenamiento:
previous_word_idx = None
label_ids = []
for word_idx in words_id:
if word_idx is None or word_idx == previous_word_idx:
label_ids.append(-100)
elif word_idx != previous_word_idx:
label_ids.append(word_idx)
previous_word_idx = word_idx
labels = [index2tag[l] if l != -100 else "IGN" for l in label_ids]
index = ["Token", "Word IDs", "Label IDs", "Labels"]
pd.DataFrame([tokens, words_id, label_ids, labels], index).T
| Token | Word IDs | Label IDs | Labels | |
|---|---|---|---|---|
| 0 | <s> | None | -100 | IGN |
| 1 | ▁Fe | 0 | 0 | O |
| 2 | cha | 0 | -100 | IGN |
| 3 | ▁de | 1 | 1 | B-NOMBRE_SUJETO_ASISTENCIA |
| 4 | ▁na | 2 | 2 | I-NOMBRE_SUJETO_ASISTENCIA |
| 5 | cimiento | 2 | -100 | IGN |
| 6 | ▁: | 3 | 3 | B-ID_SUJETO_ASISTENCIA |
| 7 | ▁01 | 4 | 4 | B-ID_ASEGURAMIENTO |
| 8 | ▁/ | 5 | 5 | I-ID_ASEGURAMIENTO |
| 9 | ▁01 | 6 | 6 | B-CALLE |
| 10 | ▁/ | 7 | 7 | I-CALLE |
| 11 | ▁1987 | 8 | 8 | B-TERRITORIO |
| 12 | ▁ | 9 | 9 | B-FECHAS |
| 13 | . | 9 | -100 | IGN |
| 14 | </s> | None | -100 | IGN |
Note
¿Por qué elegimos -100 como el ID para enmascarar las representaciones de subpalabras? La razón es que en PyTorch la clase de pérdida de entropía cruzada torch.nn.CrossEntropyLoss tiene un atributo llamado ignore_index cuyo valor es -100. Este índice se ignora durante el entrenamiento, por lo que podemos utilizarlo para ignorar los tokens asociados a subpalabras consecutivas.
Y ya está. Podemos ver claramente cómo los IDs de las etiquetas se alinean con los tokens, así que vamos a escalar esto a todo el conjunto de datos definiendo una única función que envuelva toda la lógica:
def tokenize_and_align_labels(examples):
tokenized_inputs = xlmr_tokenizer(examples["tokens"], truncation=True,
is_split_into_words=True, max_length=512)
labels = []
for idx, label in enumerate(examples["ner_tags"]):
word_ids = tokenized_inputs.word_ids(batch_index=idx)
previous_word_idx = None
label_ids = []
for word_idx in word_ids:
if word_idx is None or word_idx == previous_word_idx:
label_ids.append(-100)
else:
label_ids.append(label[word_idx])
previous_word_idx = word_idx
labels.append(label_ids)
tokenized_inputs["labels"] = labels
return tokenized_inputs
Ahora tenemos todos los ingredientes que necesitamos para codificar cada división, así que vamos a escribir una función sobre la que podamos iterar:
def encode_meddocan_dataset(corpus):
return corpus.map(tokenize_and_align_labels, batched=True,
remove_columns=['ner_tags', 'tokens'])
Al aplicar esta función a un objeto DatasetDict, obtenemos un objeto Dataset codificado por división. Usemos esto para codificar nuestro corpus Meddocan:
meddocan_encoded = encode_meddocan_dataset(ds)
Ahora que tenemos un modelo y un conjunto de datos, tenemos que definir una métrica de performance.
5.4.7. Medidas de Performance#
Como lo sabemos, la evaluación de un modelo NER es similar a la evaluación de un modelo de clasificación de textos, y es habitual informar de los resultados de precisión, recuperación y puntuación \(F_{1}\). La única sutileza es que todas las palabras de una entidad deben predecirse correctamente para que la predicción se considere correcta. Para cambiar vamos a utilizar una ingeniosa biblioteca llamada seqeval que está diseñada para este tipo de tareas. Por ejemplo, dadas algunas etiquetas NER y predicciones del modelo, podemos calcular las métricas mediante la función classification_report() de seqeval:
from seqeval.metrics import classification_report
y_true = [["O", "O", "O", "B-MISC", "I-MISC", "I-MISC", "O"],
["B-PER", "I-PER", "O"]]
y_pred = [["O", "O", "B-MISC", "I-MISC", "I-MISC", "I-MISC", "O"],
["B-PER", "I-PER", "O"]]
print(classification_report(y_true, y_pred))
precision recall f1-score support
MISC 0.00 0.00 0.00 1
PER 1.00 1.00 1.00 1
micro avg 0.50 0.50 0.50 2
macro avg 0.50 0.50 0.50 2
weighted avg 0.50 0.50 0.50 2
Note
Hay que subrayar que la métricas definida por seqeval se calculan aquí a nivel de tokens, mientras que en la evaluación final, véase capítulo Section 1 se calculan a nivel de Spans.
Como podemos ver, seqeval espera las predicciones y las etiquetas como listas de listas, con cada lista correspondiente a un solo ejemplo en nuestros conjuntos de validación o prueba. Para integrar estas métricas durante el entrenamiento, necesitamos una función que pueda tomar las salidas del modelo y convertirlas en las listas que seqeval espera. Lo siguiente hace el truco asegurando que ignoramos los IDs de etiquetas asociados con subpalabras posteriores:
import numpy as np
def align_predictions(predictions, label_ids):
preds = np.argmax(predictions, axis=2)
batch_size, seq_len = preds.shape
labels_list, preds_list = [], []
for batch_idx in range(batch_size):
example_labels, example_preds = [], []
for seq_idx in range(seq_len):
# Ignore label IDs = -100
if label_ids[batch_idx, seq_idx] != -100:
example_labels.append(index2tag[label_ids[batch_idx][seq_idx]])
example_preds.append(index2tag[preds[batch_idx][seq_idx]])
labels_list.append(example_labels)
preds_list.append(example_preds)
return preds_list, labels_list
Una vez que disponemos de una métrica de rendimiento, podemos pasar a entrenar el modelo.
5.4.8. Ajuste fino de XLM-Roberta#
Ahora tenemos todos los ingredientes para poner afinar nuestro modelo.
from transformers import TrainingArguments
downsample = 0.05
num_epochs = 3
batch_size = 4
logging_steps = len(ds["train"])*downsample // batch_size
model_name = f"{xlmr_model_name}-finetuned-meddocan"
training_args = TrainingArguments(
output_dir=model_name, log_level="error", num_train_epochs=num_epochs,
per_device_train_batch_size=batch_size, learning_rate=5e-6,
warmup_ratio=0.05, per_device_eval_batch_size=batch_size,
evaluation_strategy="epoch", save_steps=1e6, weight_decay=0.01,
disable_tqdm=False, logging_steps=logging_steps, push_to_hub=False,
remove_unused_columns=True)
Aquí evaluamos las predicciones del modelo en el conjunto de validación al final de cada epoch, ajustamos el decaimiento del peso, y establecemos save_steps a un número grande para desactivar el checkpointing y así acelerar el entrenamiento.
También necesitamos decirle al Trainer cómo calcular las métricas en el conjunto de validación, así que aquí podemos usar la función align_predictions() que definimos antes para extraer las predicciones y las etiquetas en el formato que necesita seqeval para calcular la puntuación F1:
from seqeval.metrics import f1_score
def compute_metrics(eval_pred):
y_pred, y_true = align_predictions(eval_pred.predictions,
eval_pred.label_ids)
return {"f1": f1_score(y_true, y_pred)}
El último paso es definir un data collator para que podamos rellenar cada secuencia de entrada con la mayor longitud de secuencia en un lote. HuggingFace Transformers proporciona un colador de datos dedicado para la clasificación de tokens que rellenará las etiquetas junto con las entradas:
from transformers import DataCollatorForTokenClassification
data_collator = DataCollatorForTokenClassification(xlmr_tokenizer)
El relleno de las etiquetas es necesario porque, al contrario que en una tarea de clasificación de texto, las etiquetas son también secuencias. Un detalle importante aquí es que las secuencias de etiquetas se rellenan con el valor -100, que, como hemos visto, es ignorado por las funciones de pérdida de PyTorch.
Inicializamos un nuevo modelo para cada Trainer creando un método model_init(). Este método carga un modelo no entrenado y se llama al principio de la llamada a train():
def model_init():
model = (XLMRobertaForTokenClassification
.from_pretrained(xlmr_model_name, config=xlmr_config)
.to(device))
model.model_parallel = False
return model
Ahora podemos pasar toda esta información junto con los conjuntos de datos codificados al Trainer:
indexes = {}
for split in ["train", "dev"]:
indexes[split] = range(int(meddocan_encoded[split].num_rows * downsample))
Usamos el método select() para dividir el tamaño de nuestro dataset a fin de acortar el entrenamiento.
from transformers import Trainer
trainer = Trainer(model_init=model_init, args=training_args,
data_collator=data_collator,
compute_metrics=compute_metrics,
train_dataset=meddocan_encoded["train"].select(indexes["train"]),
eval_dataset=meddocan_encoded["dev"].select(indexes["dev"]),
tokenizer=xlmr_tokenizer)
y luego ejecutar el bucle de entrenamiento como sigue:
train_output = trainer.train()
| Epoch | Training Loss | Validation Loss | F1 |
|---|---|---|---|
| 1 | 1.699400 | 0.855253 | 0.000000 |
| 2 | 0.659100 | 0.556888 | 0.129032 |
| 3 | 0.486100 | 0.463781 | 0.250000 |
Vamos a cargar un modelo que hemos entrenado previamente con todos los datos y con 150 iteraciones.
from pathlib import Path
import torch
pretrained_loc = "GuiGel/xlm-roberta-large-finetuned-meddocan"
model = XLMRobertaForTokenClassification.from_pretrained(pretrained_loc).to(device)
Vamos a evaluar este modelo para conocer sus métricas sobre el conjunto de datos de validación.
trainer.model = model
evals = trainer.evaluate()
pd.DataFrame.from_dict(evals, orient="index", columns=["evaluation"])
| evaluation | |
|---|---|
| eval_loss | 0.023452 |
| eval_f1 | 0.973730 |
| eval_runtime | 14.742900 |
| eval_samples_per_second | 17.839000 |
| eval_steps_per_second | 4.477000 |
| epoch | 3.000000 |
El modelo tiene una puntuación \(F_{1}\) micro excelente de 97.39 sobre el conjunto de datos de desarrollo. Para confirmar que nuestro modelo funciona como se espera, vamos a probarlo con una muestra de nuestro dataset de test:
text = ds["test"][10]["text"]
tag_text(text, tags, model, xlmr_tokenizer).T
| Tokens | Tags | |
|---|---|---|
| 0 | <s> | O |
| 1 | ▁Médico | O |
| 2 | : | O |
| 3 | ▁Ne | B-NOMBRE_PERSONAL_SANITARIO |
| 4 | rea | B-NOMBRE_PERSONAL_SANITARIO |
| 5 | ▁Sen | I-NOMBRE_PERSONAL_SANITARIO |
| 6 | arri | I-NOMBRE_PERSONAL_SANITARIO |
| 7 | aga | I-NOMBRE_PERSONAL_SANITARIO |
| 8 | ▁Ruiz | I-NOMBRE_PERSONAL_SANITARIO |
| 9 | ▁de | I-NOMBRE_PERSONAL_SANITARIO |
| 10 | ▁la | I-NOMBRE_PERSONAL_SANITARIO |
| 11 | ▁Illa | I-NOMBRE_PERSONAL_SANITARIO |
| 12 | ▁No | O |
| 13 | Col | O |
| 14 | : | O |
| 15 | ▁20 | B-ID_TITULACION_PERSONAL_SANITARIO |
| 16 | ▁20 | I-ID_TITULACION_PERSONAL_SANITARIO |
| 17 | ▁ | I-ID_TITULACION_PERSONAL_SANITARIO |
| 18 | 349 | I-ID_TITULACION_PERSONAL_SANITARIO |
| 19 | 13 | I-ID_TITULACION_PERSONAL_SANITARIO |
| 20 | . | O |
| 21 | </s> | O |
El resultado parece convincente. Ahora aplicamos el mismo modelo sobre el texto ya tokenizado.
toks = ds["test"][10]["tokens"]
def tag_tokens(toks, tags, model, tokenizer):
# Get sub tokens from tokens
tokens = tokenizer(toks, is_split_into_words=True, truncation=True, return_tensors="pt")
# Encode the sequence into IDs
input_ids = tokens.input_ids.to(device)
# Get predictions as distribution over 45 possible classes
outputs = model(input_ids)[0]
# Take argmax to get most likely class per token
predictions = torch.argmax(outputs, dim=2)
# Verify that there is the same number of words ids then prediction
assert len(tokens.word_ids()) == predictions.shape[1]
# Associate each tokens with the ner tag of the first subtoken
words_tag = []
previous_word_idx = -1
preds = [tags.names[p] for p in predictions[0].cpu().numpy()]
for i, (word_idx, pred) in enumerate(zip(tokens.word_ids(), preds)):
if word_idx is not None and previous_word_idx != word_idx and pred is not None:
words_tag.append(pred)
previous_word_idx = word_idx
# Visualize with a DataFrame
df = pd.DataFrame([toks, words_tag], index=["Tokens", "Ner Tags"]).T
return df
tag_tokens(toks, tags, model, xlmr_tokenizer)
| Tokens | Ner Tags | |
|---|---|---|
| 0 | Médico | O |
| 1 | : | O |
| 2 | Nerea | B-NOMBRE_PERSONAL_SANITARIO |
| 3 | Senarriaga | I-NOMBRE_PERSONAL_SANITARIO |
| 4 | Ruiz | I-NOMBRE_PERSONAL_SANITARIO |
| 5 | de | I-NOMBRE_PERSONAL_SANITARIO |
| 6 | la | I-NOMBRE_PERSONAL_SANITARIO |
| 7 | Illa | I-NOMBRE_PERSONAL_SANITARIO |
| 8 | O | |
| 9 | NºCol | O |
| 10 | : | B-ID_TITULACION_PERSONAL_SANITARIO |
| 11 | 20 | I-ID_TITULACION_PERSONAL_SANITARIO |
| 12 | 20 | I-ID_TITULACION_PERSONAL_SANITARIO |
| 13 | 34913 | O |
| 14 | . | None |
Funciona. Pero nunca debemos confiar demasiado en el rendimiento basándonos en un solo ejemplo. En su lugar, debemos realizar una investigación adecuada y exhaustiva de los errores del modelo. En la siguiente sección estudiamos cómo hacerlo para la tarea NER.
5.4.9. Análisis del Error#
Vamos a dedicar un minuto a investigar los errores de nuestro modelo. Un análisis exhaustivo de los errores de nuestro modelo es uno de los aspectos más importantes a la hora de entrenar y depurar transformadores (y modelos de aprendizaje automático en general). Hay varios modos de fallo en los que puede parecer que el modelo funciona bien, mientras que en la práctica tiene algunos fallos graves. Algunos ejemplos en los que el entrenamiento puede fallar son
Podríamos enmascarar accidentalmente demasiados tokens y también enmascarar algunas de nuestras etiquetas para obtener una caída de pérdidas realmente prometedora.
La función
compute_metrics()podría tener un error que sobrestima el verdadero rendimiento.Podríamos incluir la clase cero o la entidad O en NER como una clase normal, lo que sesgaría mucho la precisión y la puntuación F1, ya que es la clase mayoritaria por un gran margen.
Cuando el modelo funciona mucho peor de lo esperado, el examen de los errores puede aportar información útil y revelar fallos que serían difíciles de detectar con sólo mirar el código. E incluso si el modelo funciona bien y no hay errores en el código, el análisis de errores sigue siendo una herramienta útil para entender los puntos fuertes y débiles del modelo. Estos son aspectos que siempre debemos tener en cuenta cuando desplegamos un modelo en un entorno de producción.
Para nuestro análisis, volveremos a utilizar una de las herramientas más potentes de las que disponemos, que es mirar los ejemplos de validación con mayor pérdida. Calcularemos una pérdida por token en la secuencia de muestras.
Definamos un método que podamos aplicar al conjunto de validación:
from torch.nn.functional import cross_entropy
def forward_pass_with_label(batch):
# Remove keys from batch
batch = dict(filter(lambda x: x[0] not in ["text", "origin", "ner_tags_str"],
batch.items()))
# Convert dict of lists to list of dicts suitable for data collator
features = [dict(zip(batch, t)) for t in zip(*batch.values())]
# Pad inputs and labels and put all tensors on device
batch = data_collator(features)
input_ids = batch["input_ids"].to(device)
attention_mask = batch["attention_mask"].to(device)
labels = batch["labels"].to(device)
with torch.no_grad():
# Pass data through model
output = trainer.model(input_ids, attention_mask)
# logit.size: [batch_size, sequence_length, classes]
# Predict class with largest logit value on classes axis
predicted_label = torch.argmax(output.logits, axis=-1).cpu().numpy()
# Calculate loss per token after flattening batch dimension with view
loss = cross_entropy(output.logits.view(-1, 45),
labels.view(-1), reduction="none")
# Unflatten batch dimension and convert to numpy array
loss = loss.view(len(input_ids), -1).cpu().numpy()
return {"loss":loss, "predicted_label": predicted_label}
Ahora podemos aplicar esta función a todo el conjunto de validación utilizando map() y cargar todos los datos en un DataFrame para su posterior análisis:
valid_set = meddocan_encoded["dev"]
valid_set = valid_set.map(forward_pass_with_label, batched=True, batch_size=2,
remove_columns= ["text", "origin", "ner_tags_str"])
df = valid_set.to_pandas()
Parameter 'function'=<function forward_pass_with_label at 0x7f4200b550d0> of the transform datasets.arrow_dataset.Dataset._map_single couldn't be hashed properly, a random hash was used instead. Make sure your transforms and parameters are serializable with pickle or dill for the dataset fingerprinting and caching to work. If you reuse this transform, the caching mechanism will consider it to be different from the previous calls and recompute everything. This warning is only showed once. Subsequent hashing failures won't be showed.
Los tokens y las etiquetas siguen codificados con sus IDs, así que vamos a mapear los tokens y las etiquetas de nuevo a cadenas para que sea más fácil leer los resultados. A los tokens de relleno con etiqueta -100 les asignamos una etiqueta especial, IGN, para poder filtrarlos después. También nos deshacemos de todo el relleno en los campos loss y predicted_label truncándolos a la longitud de las entradas:
index2tag[-100] = "IGN"
df["input_tokens"] = df["input_ids"].apply(xlmr_tokenizer.convert_ids_to_tokens)
df["predicted_label"] = df["predicted_label"].apply(lambda x: [index2tag[i] for i in x])
df["labels"] = df["labels"].apply(lambda x: [index2tag[i] for i in x])
df['loss'] = df.apply(lambda x: x['loss'][:len(x['input_ids'])], axis=1)
df['predicted_label'] = df.apply(lambda x: x['predicted_label'][:len(x['input_ids'])], axis=1)
df.head(1).T
| 0 | |
|---|---|
| input_ids | [0, 853, 4007, 3911, 196, 152, 59629, 21713, 3... |
| attention_mask | [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, ... |
| labels | [IGN, O, IGN, IGN, O, O, B-NOMBRE_PERSONAL_SAN... |
| loss | [0.0, 5.960463e-07, 0.0, 0.0, 7.152555e-07, 5.... |
| predicted_label | [I-CORREO_ELECTRONICO, O, O, O, O, O, B-NOMBRE... |
| input_tokens | [<s>, ▁Re, mit, ido, ▁por, ▁:, ▁Roberto, ▁Gall... |
Cada columna contiene una lista de tokens, etiquetas, etiquetas previstas, etc. para cada muestra. Echemos un vistazo a los tokens individualmente descomponiendo estas listas. La función pandas.Series.explode() nos permite hacer exactamente eso en una línea creando una fila para cada elemento de la lista original de filas. Como todas las listas de una fila tienen la misma longitud, podemos hacer esto en paralelo para todas las columnas. También eliminamos las fichas de relleno que llamamos IGN, ya que su pérdida es cero de todos modos. Finalmente, convertimos las pérdidas, que siguen siendo objetos numpy.Array, en floats estándar:
df_tokens = df.apply(pd.Series.explode)
df_tokens = df_tokens[df_tokens["labels"] != "IGN"]
df_tokens["loss"] = df_tokens["loss"].astype(float).round(2)
df_tokens.head(10)
| input_ids | attention_mask | labels | loss | predicted_label | input_tokens | |
|---|---|---|---|---|---|---|
| 0 | 853 | 1 | O | 0.0 | O | ▁Re |
| 0 | 196 | 1 | O | 0.0 | O | ▁por |
| 0 | 152 | 1 | O | 0.0 | O | ▁: |
| 0 | 59629 | 1 | B-NOMBRE_PERSONAL_SANITARIO | 0.0 | B-NOMBRE_PERSONAL_SANITARIO | ▁Roberto |
| 0 | 21713 | 1 | I-NOMBRE_PERSONAL_SANITARIO | 0.0 | I-NOMBRE_PERSONAL_SANITARIO | ▁Gall |
| 0 | 52813 | 1 | I-NOMBRE_PERSONAL_SANITARIO | 0.0 | I-NOMBRE_PERSONAL_SANITARIO | ▁Pina |
| 0 | 46348 | 1 | O | 0.0 | O | ▁Corre |
| 0 | 37697 | 1 | O | 0.0 | O | ▁electrónico |
| 0 | 152 | 1 | O | 0.0 | O | ▁: |
| 0 | 2062 | 1 | B-CORREO_ELECTRONICO | 0.0 | B-CORREO_ELECTRONICO | ▁ro |
Con los datos en esta forma, ahora podemos agruparlos por los tokens de entrada y agregar las pérdidas de cada token con el recuento, la media y la suma. Por último, ordenamos los datos agregados por la suma de las pérdidas y vemos qué tokens han acumulado más pérdidas en el conjunto de validación:
(
df_tokens.groupby("input_tokens")[["loss"]]
.agg(["count", "mean", "sum"])
.droplevel(level=0, axis=1) # Get rid of multi-level columns
.sort_values(by="sum", ascending=False)
.reset_index()
.round(2)
.head(20)
)
| input_tokens | count | mean | sum | |
|---|---|---|---|---|
| 0 | ▁ | 15810 | 0.02 | 311.82 |
| 1 | ▁de | 8298 | 0.03 | 260.94 |
| 2 | ▁- | 942 | 0.14 | 132.84 |
| 3 | ▁28 | 275 | 0.41 | 112.94 |
| 4 | ▁y | 2999 | 0.03 | 77.20 |
| 5 | ▁años | 586 | 0.10 | 61.03 |
| 6 | ▁la | 3082 | 0.02 | 49.23 |
| 7 | ▁C | 270 | 0.18 | 48.58 |
| 8 | ▁/ | 2150 | 0.02 | 47.57 |
| 9 | ▁pareja | 9 | 5.22 | 46.96 |
| 10 | ▁dos | 130 | 0.34 | 43.59 |
| 11 | ▁meses | 247 | 0.16 | 40.67 |
| 12 | ▁en | 2194 | 0.02 | 39.84 |
| 13 | ▁Merc | 3 | 12.83 | 38.49 |
| 14 | ▁5 | 193 | 0.20 | 37.66 |
| 15 | ▁matern | 4 | 9.03 | 36.12 |
| 16 | ▁Mu | 55 | 0.60 | 32.98 |
| 17 | ▁año | 62 | 0.53 | 32.95 |
| 18 | ▁Edi | 5 | 6.38 | 31.89 |
| 19 | ▁13 | 96 | 0.32 | 31.17 |
Podemos observar varios patrones en esta lista:
El espacio en blanco tiene la mayor pérdida total, lo que no es sorprendente, ya que también es el símbolo más común de la lista. Sin embargo, su pérdida media es menor que la de los demás símbolos de la lista a parte de [“de”, “y”, “la”, “/”, “en”] que se encuentra en el mismo caso. Esto significa que el modelo no tiene problemas para clasificarlos.
Palabras como “-”, “años”, “meses” y “dos” aparecen con relativa frecuencia. A menudo aparecen junto a entidades con nombre y a veces forman parte de ellas, lo que explica que el modelo pueda confundirlas.
Algunas palabras como “pareja”, “Merc”, “matern” o “Edi” tienen una pérdida media muy alta a la vez que son poco frecuentes. Los investigaremos más a fondo.
También podemos agrupar las identificaciones de las etiquetas y observar las pérdidas de cada clase:
mean_loss_per_tag = (
df_tokens.groupby("labels")[["loss"]]
.agg(["count", "mean", "sum"])
.droplevel(level=0, axis=1)
.sort_values(by="mean", ascending=False)
.reset_index()
.round(2)
.head(20)
)
mean_loss_per_tag
| labels | count | mean | sum | |
|---|---|---|---|---|
| 0 | I-ID_EMPLEO_PERSONAL_SANITARIO | 4 | 21.28 | 85.10 |
| 1 | B-ID_EMPLEO_PERSONAL_SANITARIO | 1 | 21.22 | 21.22 |
| 2 | I-OTROS_SUJETO_ASISTENCIA | 10 | 12.72 | 127.17 |
| 3 | I-PROFESION | 5 | 11.96 | 59.78 |
| 4 | B-OTROS_SUJETO_ASISTENCIA | 6 | 10.12 | 60.71 |
| 5 | I-SEXO_SUJETO_ASISTENCIA | 1 | 9.06 | 9.06 |
| 6 | B-PROFESION | 4 | 4.47 | 17.88 |
| 7 | I-FAMILIARES_SUJETO_ASISTENCIA | 36 | 3.35 | 120.53 |
| 8 | I-ID_SUJETO_ASISTENCIA | 32 | 3.11 | 99.40 |
| 9 | B-FAMILIARES_SUJETO_ASISTENCIA | 92 | 2.15 | 197.69 |
| 10 | B-INSTITUCION | 72 | 2.07 | 148.87 |
| 11 | I-INSTITUCION | 181 | 1.67 | 302.14 |
| 12 | I-PAIS | 2 | 0.60 | 1.20 |
| 13 | B-HOSPITAL | 140 | 0.58 | 81.40 |
| 14 | I-NUMERO_FAX | 10 | 0.46 | 4.64 |
| 15 | I-HOSPITAL | 443 | 0.42 | 188.15 |
| 16 | I-ID_ASEGURAMIENTO | 390 | 0.38 | 147.02 |
| 17 | I-TERRITORIO | 207 | 0.31 | 64.50 |
| 18 | B-ID_ASEGURAMIENTO | 194 | 0.26 | 50.40 |
| 19 | B-ID_SUJETO_ASISTENCIA | 292 | 0.25 | 74.45 |
Vemos que I-ID_EMPLEO_PERSONAL_SANITARIO junto con ID_EMPLEO_PERSONAL_SANITARIO tiene la mayor pérdida media, lo que significa que determinar el inicio del ID de un empleo de personal sanitario supone un reto para nuestro modelo.
¡Es un resultado esperado sabiendo que la etiqueta ID_EMPLEO_PERSONAL_SANITARIO no aparece en nuestro conjunto de datos de entrenamiento!
Para comprobar que las clases menos representada en el conjunto de datos de entrenamiento son también las que tienen una pérdida media más elevada vamos a calcular la frecuencia de las clases en el conjunto de entrenamiento y visualizar la en la nueva columna train_freq de mean_loss_per_tag.
train_set = meddocan_encoded["train"]
df_train = train_set.to_pandas()[["labels"]]
df_train["labels"] = df_train["labels"].apply(lambda x: [index2tag[i] for i in x])
df_train = df_train.apply(pd.Series.explode)
df_train = df_train[df_train["labels"] != "IGN"]
train_labels_freq = df_train["labels"].value_counts(ascending=True)
Ahora visualizamos por cada etiqueta su frecuencia en la columna train_freq de mean_loss_per_tag.
mean_loss_per_tag["train_freq"] = mean_loss_per_tag.T.apply(lambda x: train_labels_freq.to_dict().get(x["labels"], 0))
mean_loss_per_tag
| labels | count | mean | sum | train_freq | |
|---|---|---|---|---|---|
| 0 | I-ID_EMPLEO_PERSONAL_SANITARIO | 4 | 21.28 | 85.10 | 0 |
| 1 | B-ID_EMPLEO_PERSONAL_SANITARIO | 1 | 21.22 | 21.22 | 0 |
| 2 | I-OTROS_SUJETO_ASISTENCIA | 10 | 12.72 | 127.17 | 23 |
| 3 | I-PROFESION | 5 | 11.96 | 59.78 | 28 |
| 4 | B-OTROS_SUJETO_ASISTENCIA | 6 | 10.12 | 60.71 | 9 |
| 5 | I-SEXO_SUJETO_ASISTENCIA | 1 | 9.06 | 9.06 | 2 |
| 6 | B-PROFESION | 4 | 4.47 | 17.88 | 24 |
| 7 | I-FAMILIARES_SUJETO_ASISTENCIA | 36 | 3.35 | 120.53 | 133 |
| 8 | I-ID_SUJETO_ASISTENCIA | 32 | 3.11 | 99.40 | 53 |
| 9 | B-FAMILIARES_SUJETO_ASISTENCIA | 92 | 2.15 | 197.69 | 243 |
| 10 | B-INSTITUCION | 72 | 2.07 | 148.87 | 98 |
| 11 | I-INSTITUCION | 181 | 1.67 | 302.14 | 222 |
| 12 | I-PAIS | 2 | 0.60 | 1.20 | 22 |
| 13 | B-HOSPITAL | 140 | 0.58 | 81.40 | 255 |
| 14 | I-NUMERO_FAX | 10 | 0.46 | 4.64 | 30 |
| 15 | I-HOSPITAL | 443 | 0.42 | 188.15 | 850 |
| 16 | I-ID_ASEGURAMIENTO | 390 | 0.38 | 147.02 | 769 |
| 17 | I-TERRITORIO | 207 | 0.31 | 64.50 | 275 |
| 18 | B-ID_ASEGURAMIENTO | 194 | 0.26 | 50.40 | 391 |
| 19 | B-ID_SUJETO_ASISTENCIA | 292 | 0.25 | 74.45 | 567 |
Comprobamos que ID_EMPLEO_PERSONAL_SANITARIO no existe en nuestros datos de entrenamiento y que varias de las etiquetas con una pérdida elevada tienen una frecuencia baja en el conjunto de entrenamiento.
Podemos desglosar esto aún más trazando la matriz de confusión de la clasificación de tokens, donde vemos que el comienzo del sexo de un sujeto de asistencia se confunde a menudo con el token I-SEXO_SUJETO_ASISTENCIA posterior, o que el comienzo de otro sujeto de asistencia se confunde con tokens similares como I-FAMILIARES_SUJETO_ASISTENCIA o B-ID_SUJETO_ASISTENCIA o con O.
import matplotlib.pyplot as plt
from sklearn.metrics import ConfusionMatrixDisplay, confusion_matrix, classification_report
import string
cm = confusion_matrix(df_tokens["labels"], df_tokens["predicted_label"],
normalize="true", labels=tags.names)
fig, ax = plt.subplots(figsize=(20, 20))
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=tags.names)
disp.plot(cmap="Blues", values_format=".2f", ax=ax, colorbar=False,
xticks_rotation="vertical")
plt.title("Normalized confusion matrix")
plt.show()
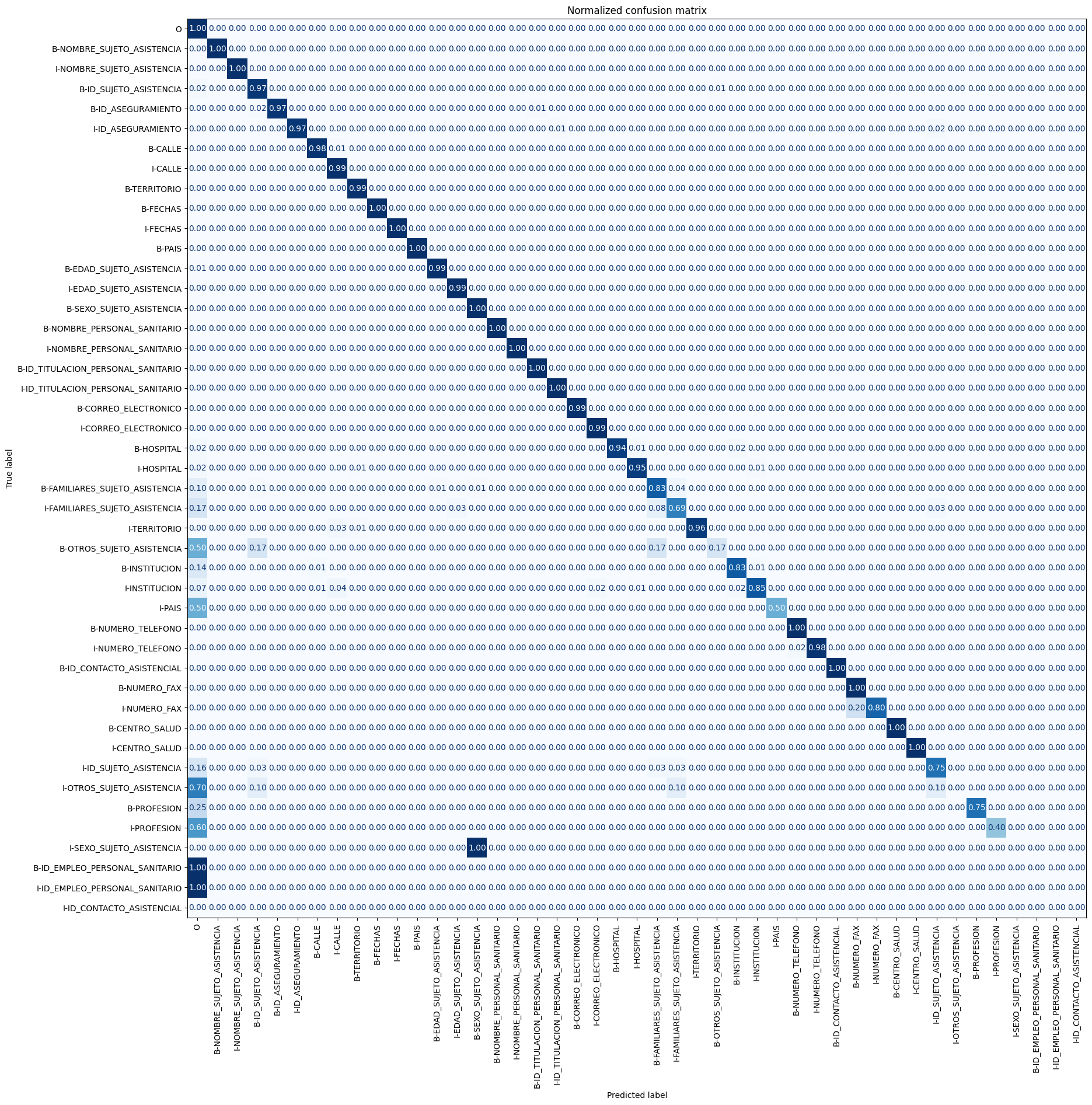
A partir del gráfico, podemos ver que nuestro modelo tiende a confundir también las entidades B-FAMILIARES_SUJETO_ASISTENCIA y I-FAMILIARES_SUJETO_ASISTENCIA entre ellas y con O. Por lo demás, es bastante bueno en la clasificación de las entidades restantes, lo que queda claro por la naturaleza casi diagonal de la matriz de confusión.
Ahora que hemos examinado los errores a nivel de token, pasemos a ver las secuencias con grandes pérdidas. Para este cálculo, volveremos a visitar nuestro DataFrame “no explotado” y calcularemos la pérdida total sumando la pérdida por token. Para ello, escribamos primero una función que nos ayude a mostrar las secuencias de tokens con las etiquetas y las pérdidas:
pd.set_option('display.max_rows', None)
def get_samples(df):
for _, row in df.iterrows():
labels, preds, tokens, losses = [], [], [], []
for i, mask in enumerate(row["attention_mask"]):
if i not in {0, len(row["attention_mask"])}:
labels.append(row["labels"][i])
preds.append(row["predicted_label"][i])
tokens.append(row["input_tokens"][i])
losses.append(f"{row['loss'][i]:.2f}")
df_tmp = pd.DataFrame({"tokens": tokens, "labels": labels,
"preds": preds, "losses": losses}).T
yield df_tmp
df["total_loss"] = df["loss"].apply(sum)
df_tmp = df.sort_values(by="total_loss", ascending=False).head(3)
for sample in get_samples(df_tmp):
display(sample.T)
| tokens | labels | preds | losses | |
|---|---|---|---|---|
| 0 | ▁ | O | O | 0.00 |
| 1 | Respons | IGN | O | 0.00 |
| 2 | able | IGN | O | 0.00 |
| 3 | ▁clínico | O | O | 0.00 |
| 4 | ▁: | O | O | 0.00 |
| 5 | ▁Dr | O | O | 0.00 |
| 6 | ▁ | O | O | 0.00 |
| 7 | . | IGN | O | 0.00 |
| 8 | ▁Lluís | B-NOMBRE_PERSONAL_SANITARIO | B-NOMBRE_PERSONAL_SANITARIO | 0.00 |
| 9 | ▁Valeri | I-NOMBRE_PERSONAL_SANITARIO | I-NOMBRE_PERSONAL_SANITARIO | 0.00 |
| 10 | o | IGN | I-NOMBRE_PERSONAL_SANITARIO | 0.00 |
| 11 | ▁Un | I-NOMBRE_PERSONAL_SANITARIO | O | 17.70 |
| 12 | idad | IGN | O | 0.00 |
| 13 | ▁de | O | O | 0.00 |
| 14 | ▁Salud | B-INSTITUCION | O | 13.89 |
| 15 | ▁Internacional | I-INSTITUCION | O | 10.41 |
| 16 | ▁B | I-INSTITUCION | B-INSTITUCION | 6.92 |
| 17 | ni | IGN | I-INSTITUCION | 0.00 |
| 18 | M | IGN | I-INSTITUCION | 0.00 |
| 19 | ▁ABS | I-INSTITUCION | B-CALLE | 14.19 |
| 20 | ▁Sta | I-INSTITUCION | I-CALLE | 15.35 |
| 21 | ▁Colo | I-INSTITUCION | I-CALLE | 14.96 |
| 22 | ma | IGN | I-CALLE | 0.00 |
| 23 | ▁de | I-INSTITUCION | I-CALLE | 15.04 |
| 24 | ▁Gra | I-INSTITUCION | I-CALLE | 15.60 |
| 25 | menet | IGN | I-CALLE | 0.00 |
| 26 | ▁6 | I-INSTITUCION | I-CALLE | 17.21 |
| 27 | ▁- | I-INSTITUCION | I-CALLE | 17.46 |
| 28 | ▁Fondo | I-INSTITUCION | I-CALLE | 17.25 |
| 29 | ▁C | B-CALLE | B-CALLE | 0.00 |
| 30 | ▁/ | I-CALLE | I-CALLE | 0.00 |
| 31 | ▁Ja | I-CALLE | I-CALLE | 0.00 |
| 32 | cin | IGN | I-CALLE | 0.00 |
| 33 | t | IGN | I-CALLE | 0.00 |
| 34 | ▁Ver | I-CALLE | I-CALLE | 0.00 |
| 35 | da | IGN | I-CALLE | 0.00 |
| 36 | guer | IGN | I-CALLE | 0.00 |
| 37 | ▁118 | I-CALLE | I-CALLE | 0.00 |
| 38 | ▁08 | B-TERRITORIO | B-TERRITORIO | 0.00 |
| 39 | 92 | IGN | B-TERRITORIO | 0.00 |
| 40 | 3 | IGN | I-TERRITORIO | 0.00 |
| 41 | ▁Santa | B-TERRITORIO | B-TERRITORIO | 0.00 |
| 42 | ▁Colo | I-TERRITORIO | I-TERRITORIO | 0.00 |
| 43 | ma | IGN | I-TERRITORIO | 0.00 |
| 44 | ▁de | I-TERRITORIO | I-TERRITORIO | 0.00 |
| 45 | ▁Gra | I-TERRITORIO | I-TERRITORIO | 0.00 |
| 46 | menet | IGN | I-TERRITORIO | 0.00 |
| 47 | ▁E | O | O | 0.00 |
| 48 | ▁- | O | O | 0.00 |
| 49 | O | O | 0.00 | |
| 50 | ▁: | O | O | 0.00 |
| 51 | ▁l | B-CORREO_ELECTRONICO | B-CORREO_ELECTRONICO | 0.00 |
| 52 | vale | IGN | B-CORREO_ELECTRONICO | 0.00 |
| 53 | rio | IGN | B-CORREO_ELECTRONICO | 0.00 |
| 54 | ▁ | I-CORREO_ELECTRONICO | I-CORREO_ELECTRONICO | 0.00 |
| 55 | . | IGN | I-CORREO_ELECTRONICO | 0.00 |
| 56 | ▁b | I-CORREO_ELECTRONICO | I-CORREO_ELECTRONICO | 0.00 |
| 57 | n | IGN | I-CORREO_ELECTRONICO | 0.00 |
| 58 | m | IGN | I-CORREO_ELECTRONICO | 0.00 |
| 59 | ▁ | I-CORREO_ELECTRONICO | I-CORREO_ELECTRONICO | 0.00 |
| 60 | . | IGN | I-CORREO_ELECTRONICO | 0.00 |
| 61 | ▁ | I-CORREO_ELECTRONICO | I-CORREO_ELECTRONICO | 0.00 |
| 62 | ics | IGN | I-CORREO_ELECTRONICO | 0.00 |
| 63 | @ | IGN | I-CORREO_ELECTRONICO | 0.00 |
| 64 | gen | IGN | I-CORREO_ELECTRONICO | 0.00 |
| 65 | cat | IGN | I-CORREO_ELECTRONICO | 0.00 |
| 66 | ▁ | I-CORREO_ELECTRONICO | I-CORREO_ELECTRONICO | 0.00 |
| 67 | . | IGN | I-CORREO_ELECTRONICO | 0.00 |
| 68 | ▁net | I-CORREO_ELECTRONICO | I-CORREO_ELECTRONICO | 0.00 |
| 69 | </s> | IGN | O | 0.00 |
| tokens | labels | preds | losses | |
|---|---|---|---|---|
| 0 | ▁Se | O | O | 0.00 |
| 1 | ▁trata | O | O | 0.00 |
| 2 | ▁de | O | O | 0.00 |
| 3 | ▁una | O | O | 0.00 |
| 4 | ▁familia | B-FAMILIARES_SUJETO_ASISTENCIA | O | 5.40 |
| 5 | ▁de | I-FAMILIARES_SUJETO_ASISTENCIA | O | 17.31 |
| 6 | ▁nu | I-FAMILIARES_SUJETO_ASISTENCIA | B-FAMILIARES_SUJETO_ASISTENCIA | 7.51 |
| 7 | eve | IGN | B-FAMILIARES_SUJETO_ASISTENCIA | 0.00 |
| 8 | ▁miembros | I-FAMILIARES_SUJETO_ASISTENCIA | O | 7.80 |
| 9 | ▁ | O | O | 0.00 |
| 10 | , | IGN | O | 0.00 |
| 11 | ▁con | O | O | 0.00 |
| 12 | ▁padres | B-FAMILIARES_SUJETO_ASISTENCIA | B-FAMILIARES_SUJETO_ASISTENCIA | 0.00 |
| 13 | ▁de | O | I-FAMILIARES_SUJETO_ASISTENCIA | 2.72 |
| 14 | ▁74 | B-EDAD_SUJETO_ASISTENCIA | I-FAMILIARES_SUJETO_ASISTENCIA | 13.05 |
| 15 | ▁y | O | I-FAMILIARES_SUJETO_ASISTENCIA | 3.41 |
| 16 | ▁64 | B-EDAD_SUJETO_ASISTENCIA | I-FAMILIARES_SUJETO_ASISTENCIA | 13.32 |
| 17 | ▁años | I-EDAD_SUJETO_ASISTENCIA | I-FAMILIARES_SUJETO_ASISTENCIA | 14.75 |
| 18 | ▁ | O | O | 0.00 |
| 19 | . | IGN | O | 0.00 |
| 20 | ▁No | O | O | 0.00 |
| 21 | ▁hay | O | O | 0.00 |
| 22 | ▁con | O | O | 0.00 |
| 23 | san | IGN | O | 0.00 |
| 24 | guin | IGN | O | 0.00 |
| 25 | idad | IGN | O | 0.00 |
| 26 | ▁y | O | O | 0.00 |
| 27 | ▁proced | O | O | 0.00 |
| 28 | en | IGN | O | 0.00 |
| 29 | ▁de | O | O | 0.00 |
| 30 | ▁localidade | O | O | 0.00 |
| 31 | s | IGN | O | 0.00 |
| 32 | ▁diferentes | O | O | 0.00 |
| 33 | ▁ | O | O | 0.00 |
| 34 | . | IGN | O | 0.00 |
| 35 | ▁La | O | O | 0.00 |
| 36 | ▁ | O | O | 0.00 |
| 37 | DG | IGN | O | 0.00 |
| 38 | ▁está | O | O | 0.00 |
| 39 | ▁presente | O | O | 0.00 |
| 40 | ▁en | O | O | 0.00 |
| 41 | ▁la | O | O | 0.00 |
| 42 | ▁madre | B-FAMILIARES_SUJETO_ASISTENCIA | B-FAMILIARES_SUJETO_ASISTENCIA | 0.00 |
| 43 | ▁ | O | O | 0.00 |
| 44 | , | IGN | O | 0.00 |
| 45 | ▁tres | B-FAMILIARES_SUJETO_ASISTENCIA | B-FAMILIARES_SUJETO_ASISTENCIA | 0.00 |
| 46 | ▁hermano | I-FAMILIARES_SUJETO_ASISTENCIA | I-FAMILIARES_SUJETO_ASISTENCIA | 0.00 |
| 47 | s | IGN | I-FAMILIARES_SUJETO_ASISTENCIA | 0.00 |
| 48 | ▁y | O | O | 0.00 |
| 49 | ▁su | O | O | 0.00 |
| 50 | ▁hijo | B-FAMILIARES_SUJETO_ASISTENCIA | B-FAMILIARES_SUJETO_ASISTENCIA | 0.00 |
| 51 | ▁ | O | O | 0.00 |
| 52 | , | IGN | O | 0.00 |
| 53 | ▁mientras | O | O | 0.00 |
| 54 | ▁que | O | O | 0.00 |
| 55 | ▁el | O | O | 0.00 |
| 56 | ▁A | O | O | 0.00 |
| 57 | OC | IGN | O | 0.00 |
| 58 | ▁aparece | O | O | 0.00 |
| 59 | ▁en | O | O | 0.00 |
| 60 | ▁dos | B-FAMILIARES_SUJETO_ASISTENCIA | O | 15.84 |
| 61 | ▁de | I-FAMILIARES_SUJETO_ASISTENCIA | O | 16.33 |
| 62 | ▁los | I-FAMILIARES_SUJETO_ASISTENCIA | O | 17.50 |
| 63 | ▁hermano | I-FAMILIARES_SUJETO_ASISTENCIA | B-FAMILIARES_SUJETO_ASISTENCIA | 11.76 |
| 64 | s | IGN | I-FAMILIARES_SUJETO_ASISTENCIA | 0.00 |
| 65 | ▁pero | O | O | 0.00 |
| 66 | ▁sin | O | O | 0.00 |
| 67 | ▁datos | O | O | 0.00 |
| 68 | ▁de | O | O | 0.00 |
| 69 | ▁ | O | O | 0.00 |
| 70 | DG | IGN | O | 0.00 |
| 71 | ▁ | O | O | 0.00 |
| 72 | . | IGN | O | 0.00 |
| 73 | </s> | IGN | O | 0.00 |
| tokens | labels | preds | losses | |
|---|---|---|---|---|
| 0 | ▁La | O | O | -0.00 |
| 1 | ▁explora | O | O | -0.00 |
| 2 | ción | IGN | O | 0.00 |
| 3 | ▁exhaust | O | O | -0.00 |
| 4 | iva | IGN | O | 0.00 |
| 5 | ▁de | O | O | -0.00 |
| 6 | ▁la | O | O | -0.00 |
| 7 | ▁paciente | O | O | 0.00 |
| 8 | ▁durante | O | O | -0.00 |
| 9 | ▁el | O | O | -0.00 |
| 10 | ▁ingreso | O | O | 0.00 |
| 11 | ▁post | O | O | 0.00 |
| 12 | operator | IGN | O | 0.00 |
| 13 | io | IGN | O | 0.00 |
| 14 | ▁no | O | O | -0.00 |
| 15 | ▁re | O | O | -0.00 |
| 16 | ve | IGN | O | 0.00 |
| 17 | ló | IGN | O | 0.00 |
| 18 | ▁les | O | O | 0.00 |
| 19 | iones | IGN | O | 0.00 |
| 20 | ▁cu | O | O | 0.00 |
| 21 | tán | IGN | O | 0.00 |
| 22 | e | IGN | O | 0.00 |
| 23 | as | IGN | O | 0.00 |
| 24 | ▁compatible | O | O | 0.00 |
| 25 | s | IGN | O | 0.00 |
| 26 | ▁con | O | O | 0.00 |
| 27 | ▁melan | O | O | 0.00 |
| 28 | oma | IGN | O | 0.00 |
| 29 | ▁ | O | O | 0.00 |
| 30 | , | IGN | O | 0.00 |
| 31 | ▁pero | O | O | 0.00 |
| 32 | ▁sí | O | O | 0.00 |
| 33 | ▁la | O | O | -0.00 |
| 34 | ▁presencia | O | O | 0.00 |
| 35 | ▁de | O | O | 0.00 |
| 36 | ▁un | O | O | 0.00 |
| 37 | ▁tatuaje | B-OTROS_SUJETO_ASISTENCIA | O | 18.82 |
| 38 | ▁en | I-OTROS_SUJETO_ASISTENCIA | O | 19.91 |
| 39 | ▁la | I-OTROS_SUJETO_ASISTENCIA | O | 19.28 |
| 40 | ▁región | I-OTROS_SUJETO_ASISTENCIA | O | 20.02 |
| 41 | ▁pe | I-OTROS_SUJETO_ASISTENCIA | O | 19.99 |
| 42 | ctor | IGN | O | 0.00 |
| 43 | al | IGN | O | 0.00 |
| 44 | ▁izquierda | I-OTROS_SUJETO_ASISTENCIA | O | 19.66 |
| 45 | ▁de | O | O | -0.00 |
| 46 | ▁10 | O | O | 0.00 |
| 47 | ▁años | O | O | 0.00 |
| 48 | ▁de | O | O | -0.00 |
| 49 | ▁anti | O | O | -0.00 |
| 50 | gü | IGN | O | 0.00 |
| 51 | edad | IGN | O | 0.00 |
| 52 | ▁ | O | O | 0.00 |
| 53 | . | IGN | O | 0.00 |
| 54 | ▁La | O | O | -0.00 |
| 55 | ▁paciente | O | O | 0.00 |
| 56 | ▁fue | O | O | 0.00 |
| 57 | ▁dada | O | O | 0.00 |
| 58 | ▁de | O | O | 0.00 |
| 59 | ▁alta | O | O | 0.00 |
| 60 | ▁hospital | O | O | 0.00 |
| 61 | aria | IGN | O | 0.00 |
| 62 | ▁a | O | O | -0.00 |
| 63 | ▁la | O | O | 0.00 |
| 64 | ▁espera | O | O | 0.00 |
| 65 | ▁de | O | O | -0.00 |
| 66 | ▁los | O | O | 0.00 |
| 67 | ▁resultados | O | O | 0.00 |
| 68 | ▁del | O | O | -0.00 |
| 69 | ▁estudio | O | O | -0.00 |
| 70 | ▁de | O | O | -0.00 |
| 71 | ▁Ana | O | O | -0.00 |
| 72 | tom | IGN | O | 0.00 |
| 73 | ía | IGN | O | 0.00 |
| 74 | ▁Pat | O | O | 0.00 |
| 75 | ológica | IGN | O | 0.00 |
| 76 | ▁ | O | O | 0.00 |
| 77 | . | IGN | O | 0.00 |
| 78 | </s> | IGN | O | 0.00 |
Otra cosa que hemos observado antes es que los tokens “pareja”, “Merc” o “matern” tienen una pérdida relativamente alta. Veamos algunos ejemplos de secuencias con el token “pareja”:
pd.set_option('display.max_rows', None)
df_tmp = df.loc[df["input_tokens"].apply(lambda x: u"\u2581pareja" in x)].head(3)
for i, sample in enumerate(get_samples(df_tmp)):
if i == 0:
display(sample.T.iloc[151:165].T)
else:
display(sample.T.iloc[40:50].T)
| 151 | 152 | 153 | 154 | 155 | 156 | 157 | 158 | 159 | 160 | 161 | 162 | 163 | 164 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| tokens | ▁de | ▁de | terior | o | ▁de | ▁la | ▁relación | ▁de | ▁pareja | ▁que | ▁manten | ía | ▁ | , |
| labels | O | O | IGN | IGN | O | O | O | O | B-FAMILIARES_SUJETO_ASISTENCIA | O | O | IGN | O | IGN |
| preds | O | O | O | O | O | O | O | O | O | O | O | O | O | O |
| losses | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 16.30 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 40 | 41 | 42 | 43 | 44 | 45 | 46 | 47 | 48 | 49 | |
|---|---|---|---|---|---|---|---|---|---|---|
| tokens | . | ▁Rela | ción | ▁de | ▁pareja | ▁estable | ▁desde | ▁hacía | ▁varios | ▁años |
| labels | IGN | O | IGN | O | B-FAMILIARES_SUJETO_ASISTENCIA | O | O | O | O | O |
| preds | O | O | O | O | O | O | O | O | O | O |
| losses | 0.00 | 0.00 | 0.00 | 0.00 | 16.20 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 40 | 41 | 42 | 43 | 44 | 45 | 46 | 47 | 48 | 49 | |
|---|---|---|---|---|---|---|---|---|---|---|
| tokens | o | ▁por | ▁parte | ▁de | ▁su | ▁pareja | ▁ | , | ▁hab | iendo |
| labels | IGN | O | O | O | O | B-FAMILIARES_SUJETO_ASISTENCIA | O | IGN | O | IGN |
| preds | O | O | O | O | O | B-FAMILIARES_SUJETO_ASISTENCIA | O | O | O | O |
| losses | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
En la primera y segunda frase vemos claramente que el token ” pareja” no se detecta correctamente como ID-OTRO_SUJETO_ASISTENCIA.
En nuestro caso, el conjunto de datos ha sido etiquetado por expertos y verificado varias veces, lo que nos permite evitar en lo posible los errores de etiquetado que no somos capaces de detectar ahora.
Con un análisis relativamente sencillo, hemos identificado algunos puntos débiles en nuestro modelo, pero no tanto en el conjunto de datos que parece estar correctamente etiquetado. En un caso de uso real, repetiríamos este paso, limpiando el conjunto de datos, volviendo a entrenar el modelo y analizando los nuevos errores hasta que estuviéramos satisfechos con el rendimiento.